The IT monitoring platform.
Scalable. Automated. Extensible.
Gain a complete view of your entire IT infrastructure: from public cloud providers, to your data centers, across servers, networks, containers, and more. Checkmk enables ITOps and DevOps teams to run your IT at peak performance.










The heart of the Checkmk platform is the High Performance Core, designed to scale up to millions of services monitored while still retaining a small footprint.
Its REST API and many automations, such as the auto-registration of hosts, take manual work off your IT team’s shoulders.
Checkmk not only monitors everything that powers your business, but also keeps it secure, thanks to granular access control, encryption, and 2FA.
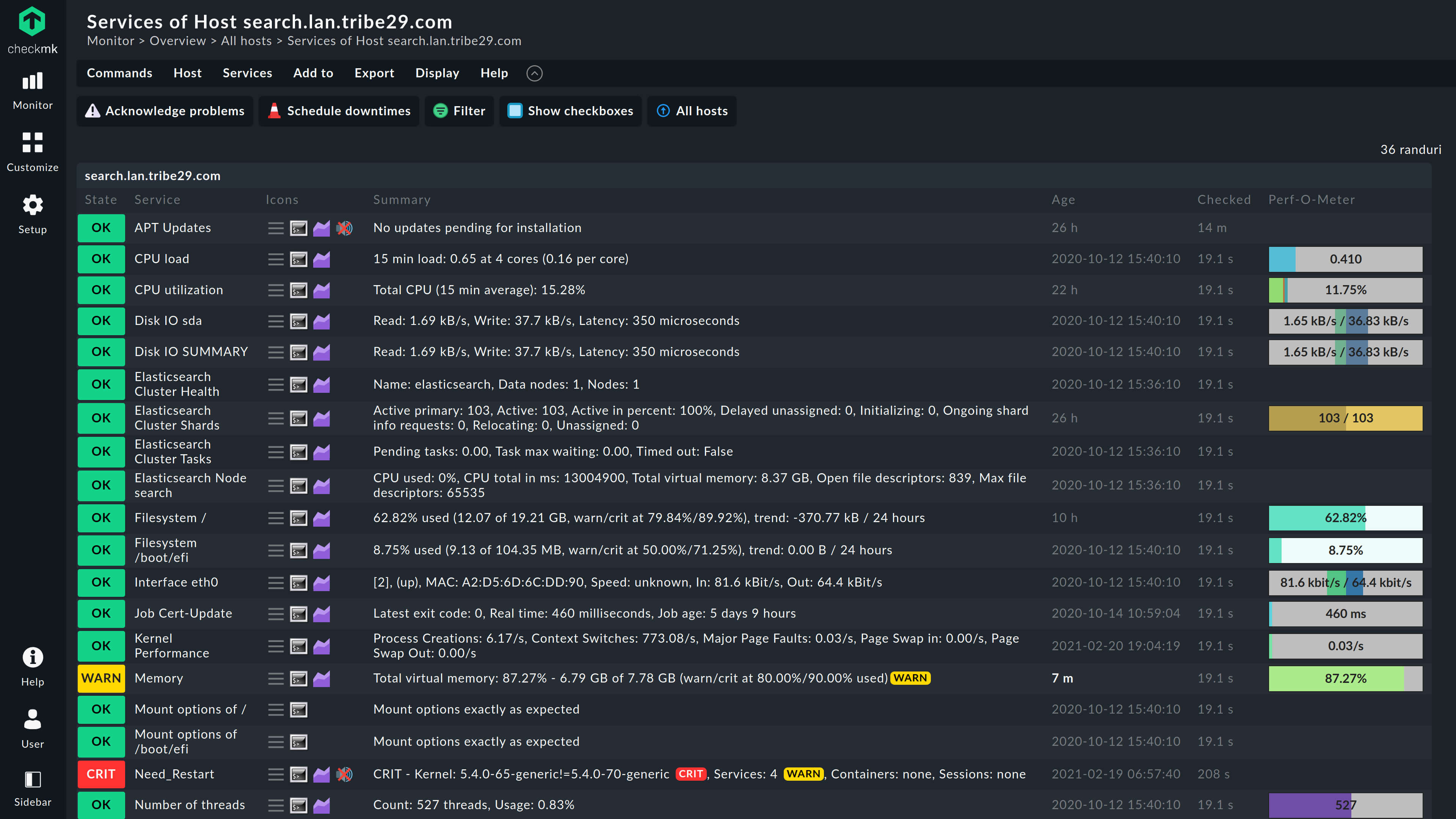
Monitor everything, don’t miss anything: our industry-leading selection of 2,000+ vendor-maintained plug-ins allows automated acquisition of health statuses and metrics from a multitude of data sources across servers, networks, clouds, containers, and applications.
Don’t waste your time deciding what to monitor and how to configure it. Checkmk is ready in minutes, recognizes automatically which data is relevant to monitor, and displays key metrics in ready-to-use graphs.
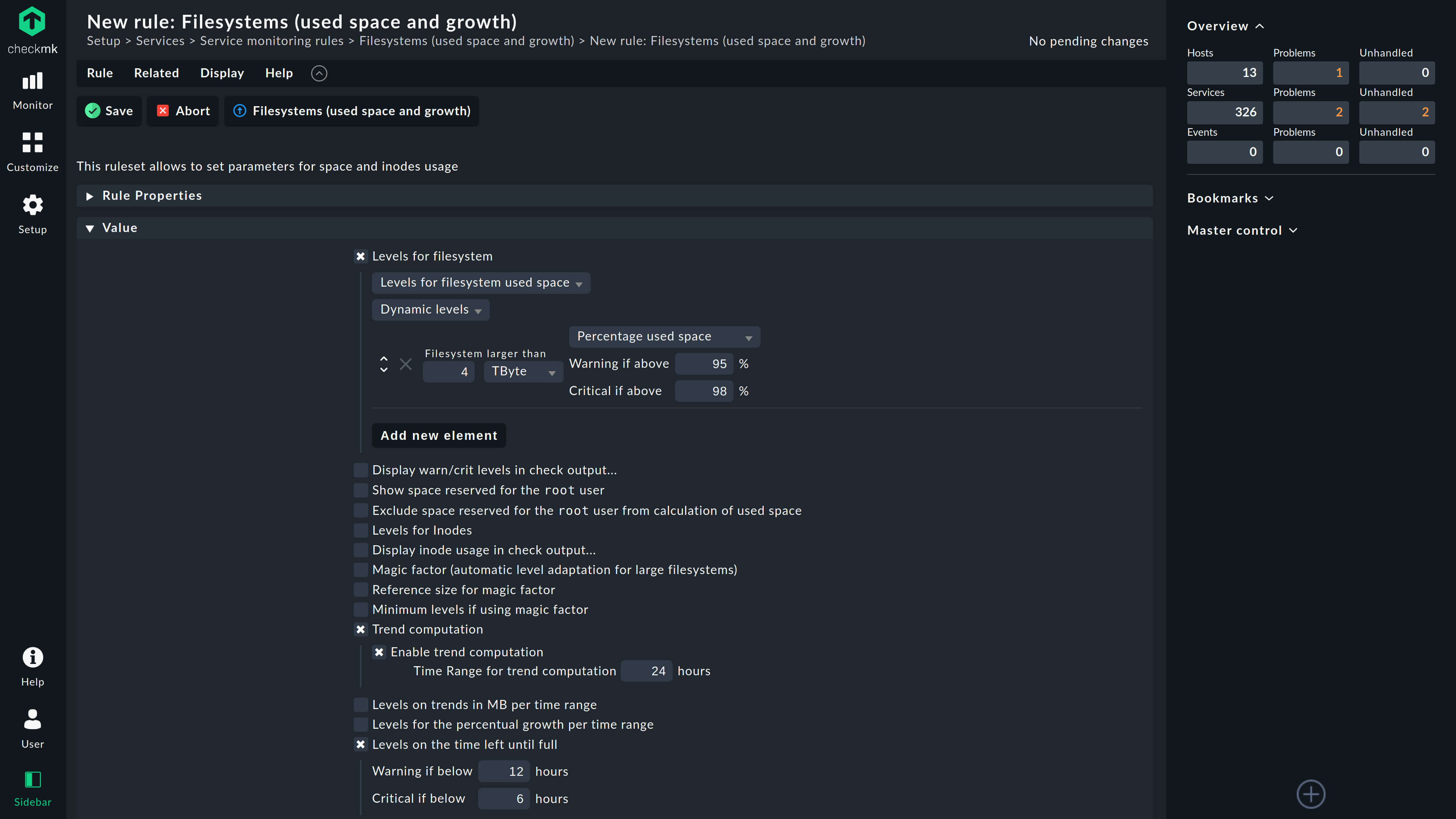
Benefit from pre-defined thresholds for alerts that provide out-of-the-box health assessment capabilities for the vast majority of hosts in your IT infrastructure.
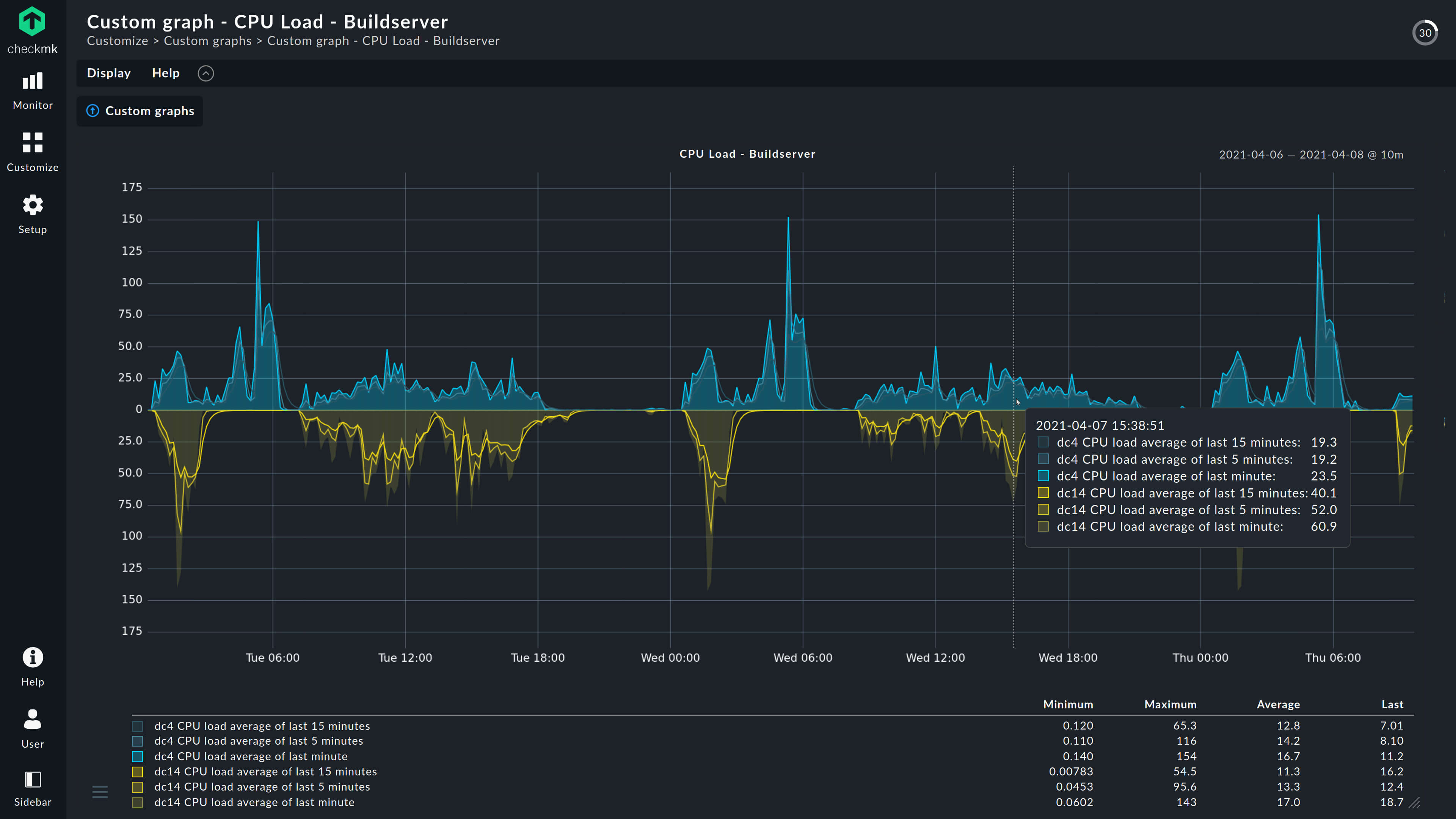
Analyze performance using built-in time-series analyzes, or compare metrics across multiple graphs at a glance.
Review historical stats to forecast your future IT infrastructure requirements, or to determine the root cause of degraded performance and abnormal behavior.
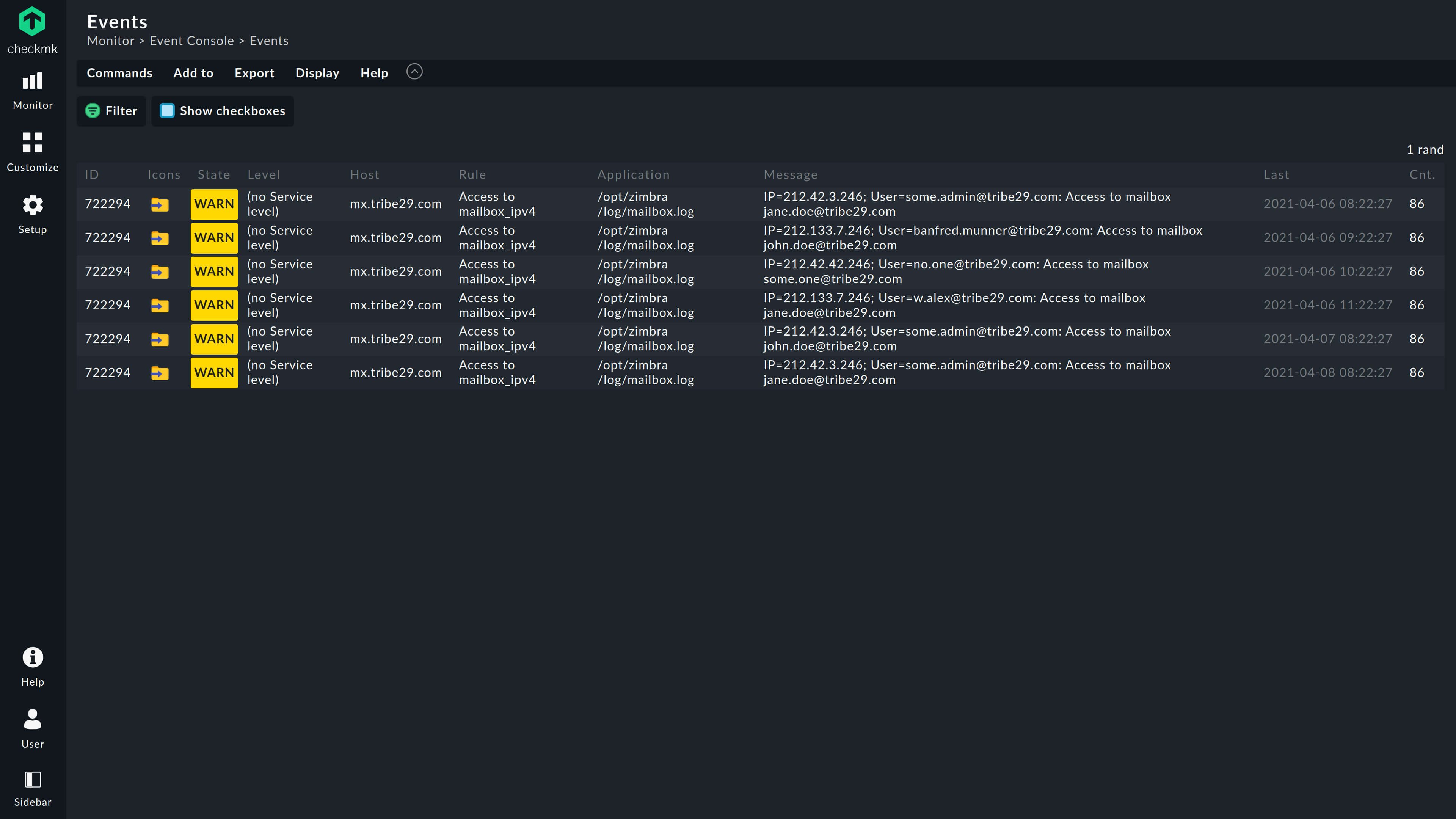
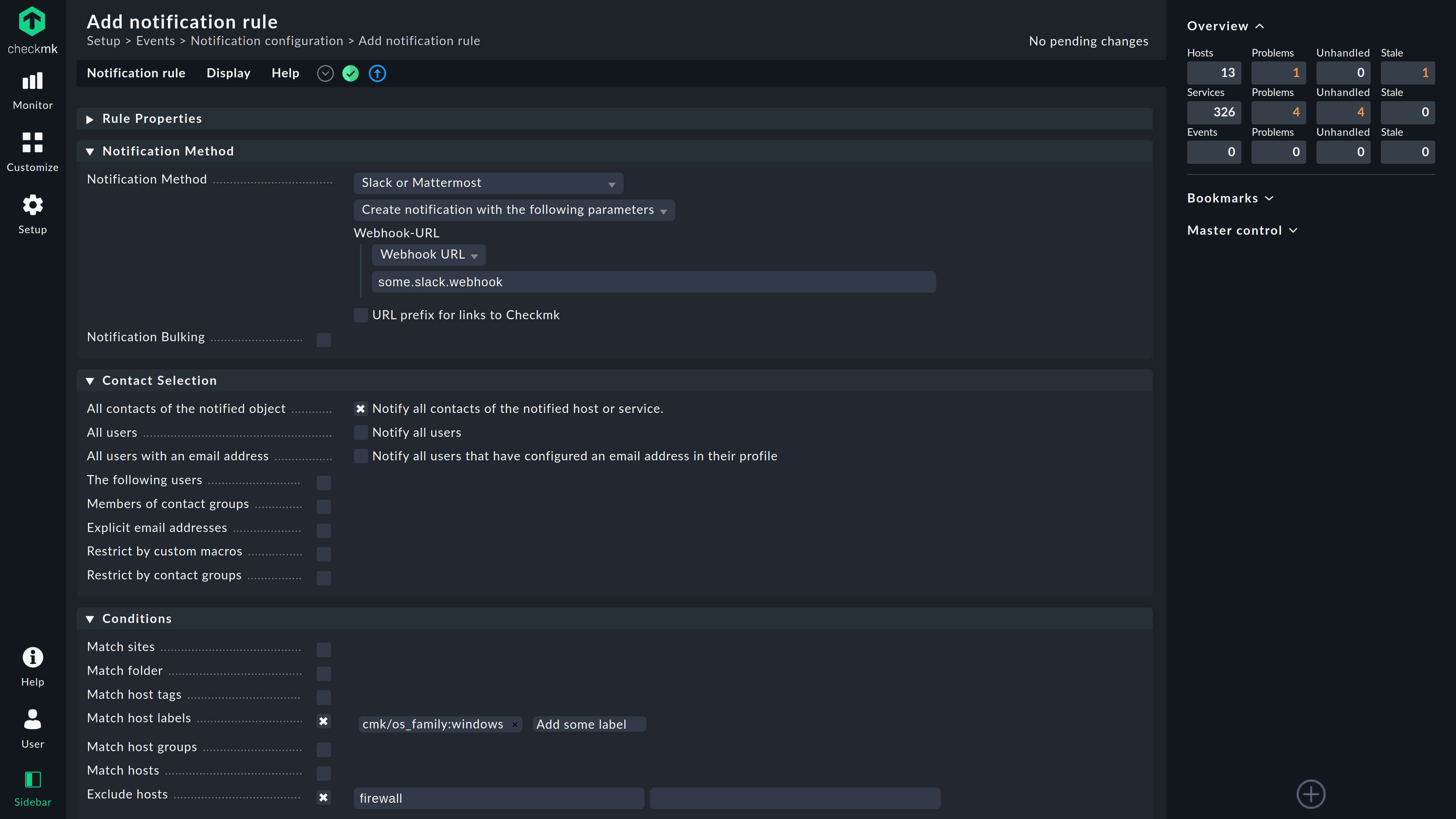
Avoid notification overload by alerting only the team responsible for a specific point of failure.
Easily configure alerts in granular manner and automate escalation of issues when they are not handled on time.
Streamline your team’s workload by automatically creating tickets in third-party tools, such as ServiceNow, Jira, and many more, or send traditional text notifications via email, SMS or Slack.
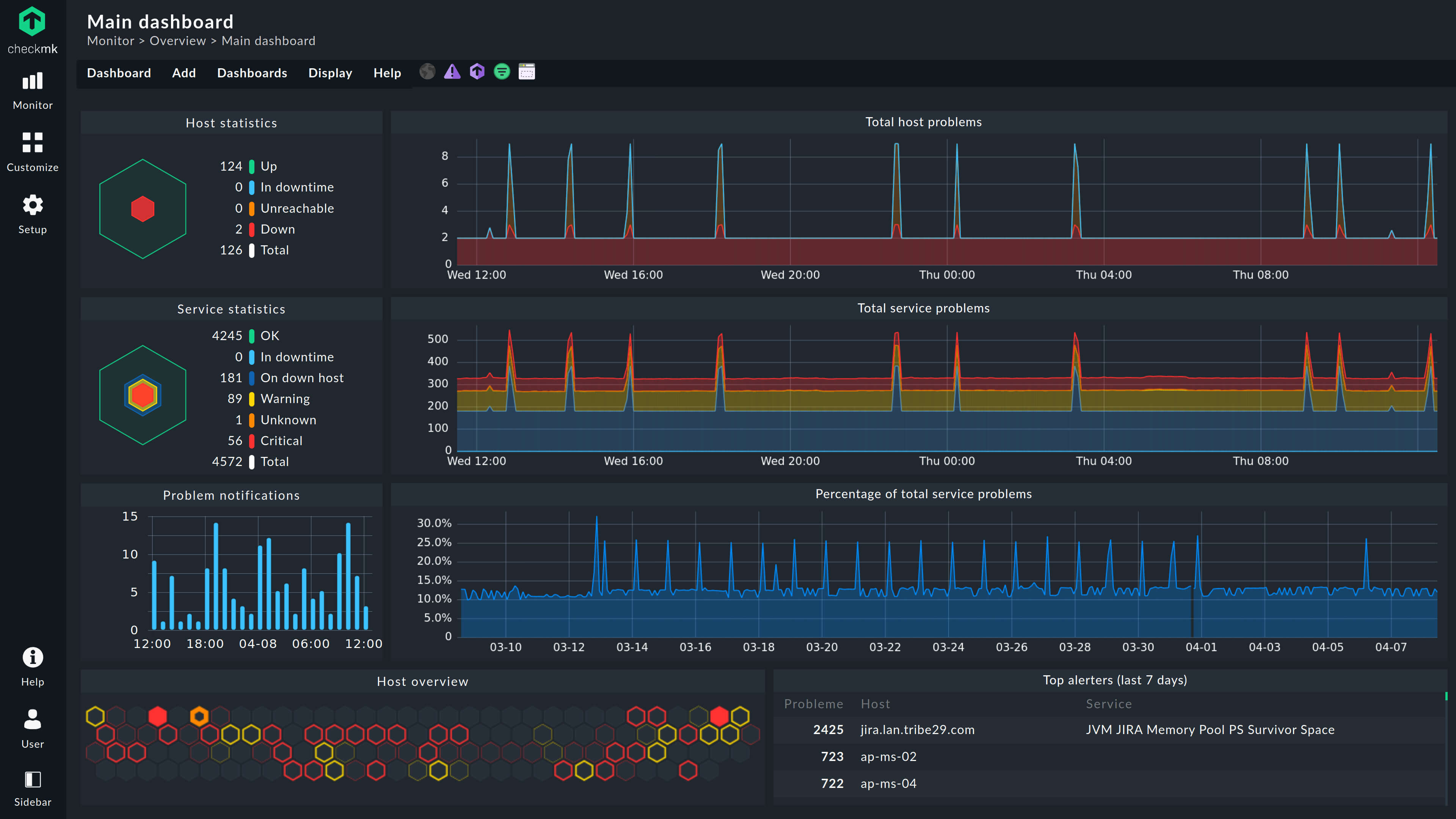
Get ultimate visibility from both built-in and custom dashboards packing key metrics and real-time insights.
Empower your strategy with Business Intelligence, which provides a bird’s-eye view on the availability and performance of key business processes, by mapping application dependencies and/or aggregating various services and hosts into a single state.
Take advantage of custom self-healing: use the alert handler to automatically trigger actions upon detection of new problems.

Monitor everything
Monitor your hybrid IT infrastructure out-of-
the-box with our leading library of more than 2,000 vendor-maintained monitoring plug-ins. See them all

Highly automated
With its auto-discovery, auto-configuration via a modern REST API, and built-in agent management, Checkmk takes manual work off your hands

Massively scalable
Monitor hundreds of thousands of hosts and millions of services across the globe, thanks to a high-performance distributed architecture

Extensible
Customize or extend the open source code of Checkmk. Use the Check-API to write your own monitoring plug-ins or extend existing ones

Optimized for any IT infrastructure.
Free and open source IT monitoring for mid-sized infrastructures.
Monitor your entire IT:
- Auto-discover your IT
- Monitor out-of-the-box with 2000+ plug-ins
- Auto-detect issues
- 100% Open Source
and more
Support: Checkmk Community
Download nowScalable and automated enterprise-wide IT monitoring.
Everything in Raw, plus:
- Accelerate and scale up your monitoring
- Automate monitoring operations
- Monitor dynamic workloads
- Visualize your IT
and much more
Support: Enterprise-grade
Learn moreState-of-the-art IT monitoring for cloud and hybrid infrastructures.
Everything in Enterprise, plus:
- Monitor cloud workloads
- Deploy from cloud marketplaces
- Auto-register any load
- Push and pull agents
- Visualize your cloud
and much more
Support: Enterprise-grade
Learn moreWhere IT monitoring experts meet.
Checkmk Raw Edition and parts of the Enterprise and Cloud Editions are open source fueled projects by our Community, where users, partners, and developers meet to support each other and contribute to make Checkmk even better. We are committed to collaborate with the source of our strength: you, our community.




