Monitoraggio dello swap di Linux: I principali approfondimenti di Checkmk
 il 5 giu 2019
il 5 giu 2019
Il sistema operativo Linux: utilizzo della memoria e monitoraggio dello swap
La mia esperienza su come monitorare la memoria in Linux risale a molto tempo fa. Tutto è iniziato nel 1992, quando Linux veniva ancora installato da dischetti, non era in grado di gestire il TCP/IP e il numero di versione iniziava con 0.99. La memoria è stata la ragione per cui mi sono accorto di questo problema.
La memoria è stata la ragione per cui sono venuto a conoscenza di Linux. Quando stavo programmando il mio primo progetto significativo in C++ (un gioco giocato per posta fisica!), avevo raggiunto i limiti della memoria ad accesso casuale (RAM) in MS-DOS ed ero alla ricerca di una soluzione. Il sistema Linux presentava un'architettura moderna che offriva uno spazio di indirizzi lineare che poteva essere esteso virtualmente all'infinito con lo swapping. Questo mi permetteva di programmare senza pensare alla memoria. Un'idea geniale, pensai, mentre scoprivo quanto lo spazio di swap aiutasse il mio lavoro!
Come monitorare il sistema Linux alla vecchia maniera
Il primo strumento per il monitoraggio della memoria è stato il comando free, che quasi tutti i Linuxer conoscono. Esso mostra il "consumo" attuale della memoria ad accesso casuale e dello swap, consentendo di controllare l'utilizzo dello spazio di swap.
mk@Klapprechner:~$ free
total used free shared buff/cache available
Mem: 16331712 2397504 9976772 222864 3957436 13369088
Swap: 32097148 553420 32097148
Naturalmente, all'epoca i numeri non erano così grandi (qui si leggono kB, non byte) e il mio computer non aveva 16 GB di spazio su disco, ma solo 4 MB!
Tuttavia, anche allora il principio era lo stesso. A quel tempo, la paura di un uso intensivo dello spazio di swap e della conseguente perdita di prestazioni era enorme. Per questo motivo, ritenevo che ogni sistema di monitoraggio server decente dovesse avere un controllo del consumo di memoria ad accesso casuale e un controllo dello spazio di swap.
Approfondimenti sull'utilizzo dello swap nello sviluppo di Checkmk
Quanto sopra è ciò che ho pensato inizialmente, finché non ho dato un'occhiata più da vicino durante lo sviluppo di Checkmk, quasi 20 anni dopo! Era abbastanza chiaro che i buffer e le cache possono essere considerati memoria libera, perché è quello che fanno (quasi) tutti i sistemi di monitoraggio.
Volevo saperne di più e ho ricercato a fondo il significato di tutte le informazioni in /proc/meminfo. In questo file, la versione del kernel Linux fornisce informazioni precise su tutti i parametri di gestione della memoria e sullo spazio di swap.
C'è molto output qui, molto di più di quanto free mostra. In alcuni casi, i comandi non erano sufficienti. Ho dovuto avventurarmi nel codice sorgente di Linux per capire esattamente i collegamenti.
Le cinque premesse che ci hanno permesso di realizzare Checkmk, lo strumento più accurato per monitorare l'utilizzo dello spazio di swap
Seguendo quanto detto sopra, sono giunto a risultati sorprendenti, che probabilmente possono dire che hanno scosso le fondamenta della mia visione su come monitorare l'utilizzo dello spazio di swap.
- La gestione di Linux è molto più ingegnosa e sofisticata di quanto pensassi. Le parole "libero" e "occupato" non rendono giustizia a ciò che accade.
- Considerare separatamente lo spazio di swap e la memoria ad accesso casuale non ha senso.
- Anche l'idea apparente di considerare i buffer/cache come
freenon è necessariamente corretta! - Molti parametri importanti non sono mostrati gratuitamente, ma possono essere critici per il funzionamento del sistema.
- Il controllo della memoria di Checkmk per Linux doveva essere completamente rielaborato per garantire un monitoraggio accurato dell'utilizzo dello swap e una corretta visualizzazione delle informazioni.
Dopo alcuni giorni di lavoro, ci siamo riusciti. A mio parere, Checkmk ha il miglior controllo della memoria Linux, il più accurato e, soprattutto, il più tecnicamente "corretto" che si possa immaginare.
Questo ha portato a un nuovo problema, molto più grande: spiegarlo! Il plug-in di controllo eseguiva i processi correttamente, funzionando a tal punto che molti utenti erano sorpresi e sospettosi dei risultati.
Che senso ha se una soglia di RAM è superiore al 100%?
Cos'è più prezioso? I processi o la cache?
Diamo un'occhiata più da vicino. Il nostro server ha 64 GB di RAM e altrettanti di partizione di swap. Il totale è di 128 GB, al massimo. E dimentichiamo il fatto che il kernel stesso ha bisogno di spazio.
Ora, supponiamo di avere un'applicazione o uno strumento che necessita di 64 GB di RAM.
Sembra meraviglioso perché l'utilizzo dello spazio di swap sarebbe minimo, giusto? La prima sorpresa: il sistema Linux è sfacciato ed esternalizza parti dei processi nella partizione di swap. Perché? Perché il kernel vorrebbe selezionare la memoria di swap per le cache. Questo non è solo un secondo uso piacevole per la memoria altrimenti vuota (come ero solito pensare), ma è fondamentale per un sistema ad alte prestazioni.
Senza il file di swap, le cose sarebbero molto complicate. Tutti i file dovrebbero essere recuperati ripetutamente dallo spazio su disco, quindi l'effetto complessivo sarebbe molto peggiore di quello che si avrebbe se alcune parti non importanti dei processi finissero nell'area di swap.
Il grafico seguente mostra l'andamento delle cache di diversi server nell'arco di una settimana. La maggior parte dello spazio è utilizzata per i contenuti dei file. In questo contesto, un file di swap è una soluzione eccellente.
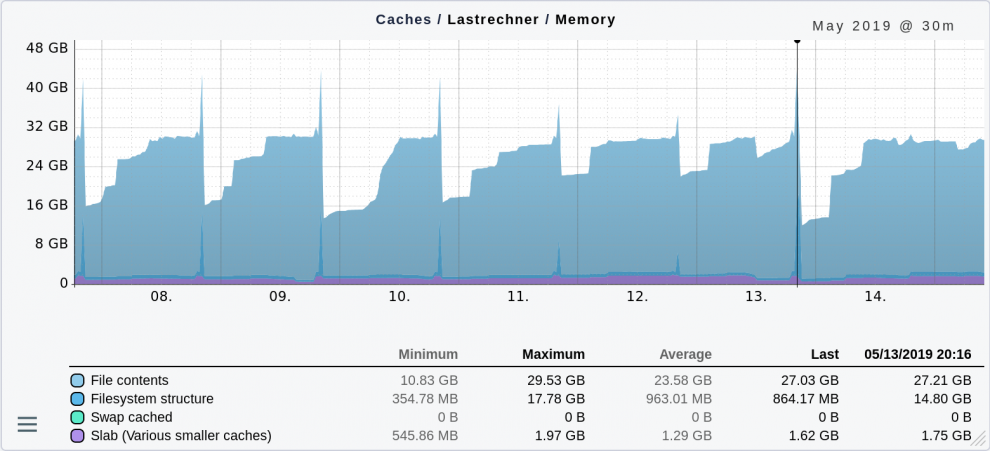
Inoltre, anche le cache per la struttura del file system (directory, nomi di file) occupano una quantità immensa di spazio una volta al giorno (fino a 17,78 GB). Non ho indagato ulteriormente, ma potrebbe essere che in quel momento sia sempre in esecuzione un backup.
I fattori esterni influenzano l'utilizzo dello spazio di swap del sistema Linux
Linux, quindi, utilizza il campo di swap molto prima e non solo quando la memoria diventa scarsa. Tale soglia dipende meno dallo stato del sistema e più da influenze esterne.
Se sono stati letti molti file, ad esempio durante un backup di dati, la cache si gonfia e i processi vengono spostati sempre più spesso nello spazio di swap.
Una volta terminato il backup, i processi rimangono nelle aree di swap per un certo periodo di tempo, anche se c'è di nuovo spazio nella RAM. Il motivo è semplice: perché sprecare la preziosa larghezza di banda dell'IO su disco per dati che potrebbero non servire mai?
Lo spazio di swap e l'utilizzo della RAM dovrebbero essere valutati insieme
Cosa significa quanto sopra per un monitoraggio significativo? Se si esamina l'uso della RAM e dello swap separatamente, si noterà che, dopo il backup dei dati, si ha più RAM libera di prima e che lo spazio di swap occupato è maggiore.
In realtà, non è cambiato nulla. Se si effettuano due controlli separati ed entrambi mostrano una curva invertita, ciò potrebbe portare a conclusioni errate e, soprattutto, a falsi allarmi.
È meglio considerare la somma della RAM e dello spazio di swap occupati. Che cosa significa? Non è altro che l'attuale consumo totale di memoria di tutti i processi, indipendentemente dalla posizione in cui i dati sono attualmente memorizzati. Questa somma e nient'altro è rilevante per la configurazione e le prestazioni del sistema.
Una soglia superiore al 100%?
Ora, naturalmente, c'è la questione di una soglia ragionevole per un allarme.
Soglie assolute, come 64 GB, sono ovviamente estremamente poco pratiche se si monitorano molti server seguendo i comandi. Ma a cosa dovrebbe riferirsi un valore relativo in percentuale?
Dal mio punto di vista, la cosa più sensata è riferire questo valore esclusivamente alla RAM. In questo caso, una soglia del 150% ha improvvisamente senso! Ciò significa che i processi possono consumare fino al 50% di memoria in più rispetto alla RAM reale. Questa misura garantisce che la maggior parte dei processi possa essere memorizzata nella RAM, anche se le cache sono ancora considerate.
Altri valori interessanti di utilizzo della memoria
Se hai mai dato un'occhiata a /proc/meminfo sarai sicuramente rimasto sorpreso dai valori in uscita e da quante informazioni si possono trovare al di là dell'uso della RAM e dello swap. Alcune di esse si riferiscono a funzioni piuttosto rilevanti.
Vorrei citarne due, che mi hanno creato problemi:
Dirty (Filesystem Writeback)
Il valore "sporco" comprende i blocchi di file che sono stati modificati dai processi ma non ancora scritti su disco.
Linux di solito aspetta fino a 30 secondi per scrivere questi blocchi, sperando di unire in modo efficiente ulteriori modifiche nello stesso blocco. In un sistema sano, anche se fortemente stressato, ecco come si presenta:
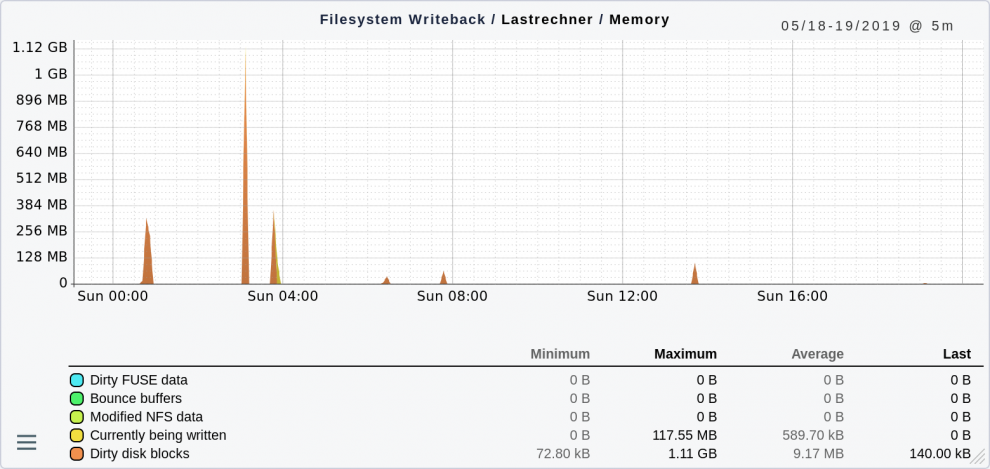
I singoli picchi mostrano situazioni in cui sono stati creati o modificati molti nuovi file in un unico ciclo. Questo non è motivo di preoccupazione perché i dati sono stati scritti su disco molto rapidamente.
Tuttavia, se si verifica una situazione di inceppamento continuo, di solito significa che c'è un collo di bottiglia nell'IO del disco. Il sistema non riesce a scrivere i dati sul disco in tempo.
Esiste un buon test per questo: andare alla riga di comando e digitare il comando sync. Questo interrompe immediatamente l'attesa di 30 secondi e scrive tutti i dati in sospeso sul disco. Dovrebbe richiedere solo pochi secondi.
Se il comando seguente dura di più, c'è da preoccuparsi. I dati modificati necessari si trovano solo nella RAM. Non c'è alcuna uscita sul disco. Questo potrebbe indicare un difetto hardware nel sottosistema del disco.
Se sync dura diverse ore, è necessario suonare il campanello d'allarme e intervenire con urgenza.
Il monitoraggio dei blocchi sporchi del disco può rilevare tali situazioni di sistema e avvisare in tempo.
Paging
Ogni processo in Linux ha una tabella che mappa gli indirizzi della memoria virtuale in quelli della memoria fisica. Questa operazione è chiamata paginazione.
La tabella mostra anche, ad esempio, dove è stato memorizzato qualcosa nello spazio di swap. Queste tabelle di paging devono essere conservate nella RAM, poiché lo swapping non è possibile. Il grafico seguente mostra un server in cui tutto è assolutamente nei limiti:
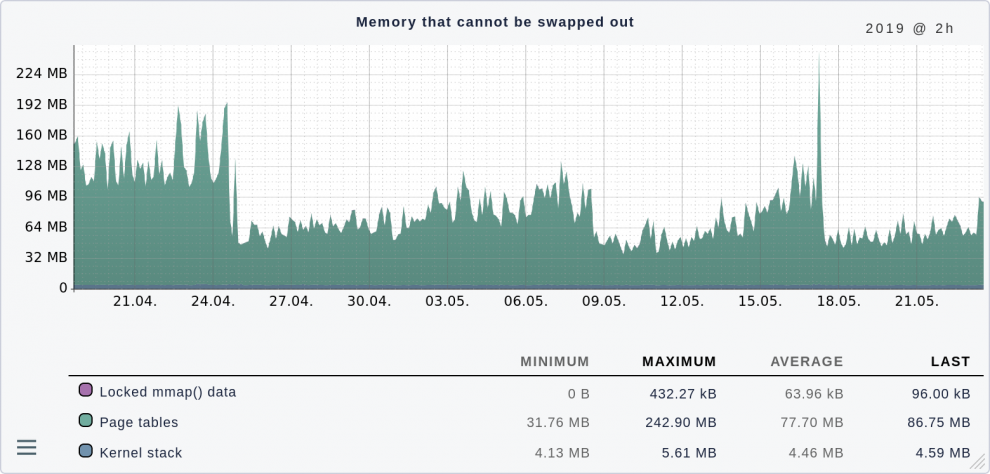
Naturalmente, un massimo di 240 MB è molto solo per queste tabelle, considerando che il mio primo computer aveva solo 4 MB. Tuttavia, con 64 GB di RAM in totale, questo non fa male.
Caso di studio: Database Oracle
La premessa
Come consulente Linux, avevo un cliente che eseguiva molti database Oracle su un grande server. L'architettura di Oracle consente a molti processi di gestire in parallelo i comandi al database e di comunicare con esso tramite la memoria condivisa. Il cliente aveva molti comandi di questo tipo attivi.
La situazione
La RAM per la memoria condivisa è davvero necessaria solo una volta, ma ogni processo ha comunque bisogno di una tabella di pagine e la memoria condivisa si riflette nuovamente in ogni tabella.
Queste tabelle hanno aggiunto più del 50% della RAM sui sistemi Linux. La cosa che mi ha confuso è che questo non era visibile nei processi in top o in strumenti simili. In qualche modo la memoria era sparita e nessuno sapeva dove fosse finita!
La soluzione
La soluzione è semplice: nei sistemi Linux è possibile attivare le cosiddette Huge Pages. Una pagina non gestisce più 512 byte, ma, ad esempio, 2 MB e le tabelle diventano molto più piccole. Ma prima è necessario trovare la causa principale. Pertanto, il controllo delle tabelle di pagina è fondamentale per un buon monitoraggio.
Conclusione
Il monitoraggio della memoria è più di una semplice soglia per la RAM "usata". Poiché la gestione della memoria è molto diversa per ogni sistema operativo, un buon monitoraggio deve conoscere e considerare le sue peculiarità. Lo spazio di swap è fondamentale per capire come funziona il sistema quando si tratta di Linux.