Monitoraggio E2E: Assicuratevi che le applicazioni funzionino
 il 16 nov 2020
il 16 nov 2020
Con il monitoraggio dell'infrastruttura o del sistema, un team IT può tenere sotto controllo lo stato di salute della propria infrastruttura IT in ogni momento. In questo modo, i problemi possono essere identificati rapidamente e facilmente e i guasti possono essere corretti prima che si ripercuotano sull'infrastruttura IT. Un'area che questo tipo di monitoraggio non copre, tuttavia, è il monitoraggio dell'esperienza dell'utente: Il software funziona come dovrebbe per l'utente o i lunghi tempi di caricamento rallentano la produttività del dipendente?
Questo problema sta diventando sempre più evidente con il crescente utilizzo di piattaforme, servizi e infrastrutture cloud nelle organizzazioni. In questi casi, l'amministratore IT spesso non ha accesso all'infrastruttura sottostante. Ciò significa che non può guardare a fondo "nel motore", come sarebbe possibile con un'infrastruttura locale. E questo rende di conseguenza molto più difficile individuare la causa di un problema che si verifica all'interno di un'applicazione.
Il monitoraggio End-to-End offre agli amministratori IT la possibilità di far luce su aree oscure all'interno del proprio ambiente IT. L'obiettivo è rendere il funzionamento dell'infrastruttura IT fornita il più fluido possibile.
Questo articolo si propone di sensibilizzare l'opinione pubblica sulla necessità di effettuare test End2End e di spiegare come integrare tali test in Checkmk.
TL;DR:
Il monitoraggio end-to-end garantisce il corretto funzionamento delle applicazioni dal punto di vista dell'utente, andando oltre i tradizionali controlli dell'infrastruttura.
- Colma il divario tra il livello 7 OSI e l'utente finale valutando l'effettiva funzionalità e le prestazioni del software così come vengono percepite dagli utenti.
- Robot Framework automatizza i test ripetitivi su applicazioni web, desktop e personalizzate, semplificando il processo di identificazione di errori, rallentamenti o arresti anomali.
- Inoltre, Robotmk integra questi test in Checkmk, consentendo l'esecuzione programmata, la raccolta dei risultati e le notifiche di avviso, permettendo agli amministratori di mantenere in modo proattivo un'esperienza utente senza interruzioni.
Orientamento nel modello OSI
Il motivo per cui il monitoraggio End2End è importante è reso chiaro osservando il modello di livello OSI. Il modello mostra ciò che un amministratore può monitorare utilizzando il monitoraggio dell'infrastruttura IT e indica dove si trova il limite naturale di questo tipo di monitoraggio.

In questo modello, i protocolli di rete si costruiscono fondamentalmente a strati. Ad esempio, la echo request del controllo ICMP attraversa i livelli 3, 2 e 1 prima di risalire attraverso il mezzo di trasmissione (aria o cavo) sull'host di destinazione attraverso i livelli 1, 2 e 3. Qui viene confermata con un pacchetto di risposta, che viene restituito nella direzione opposta.
Ciò che accade in dettaglio al pacchetto durante il suo viaggio attraverso questi livelli è irrilevante per Checkmk e non è l'argomento di questo articolo. L'importante è che la richiesta del livello 3 riceva una risposta entro un certo tempo, in modo che Checkmk possa contrassegnare l'host come "UP", cioè raggiungibile.
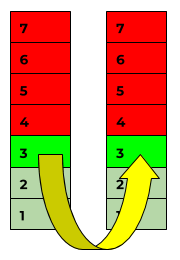
Questo perché, ad esempio, un server web deve essere in grado di fare molto di più che rispondere alle richieste ICMP; ovviamente ci sono anche check per i protocolli dei livelli superiori.
Se Checkmk controlla un host di destinazione, ad esempio, con un controllo FTP, il pacchetto in questo caso parte dal livello 7 (= il plug-in FTP), scende attraverso tutti i livelli e dopo aver raggiunto l'host di destinazione, risale fino al livello 7 dove il server FTP sta (si spera) operando. Risponde alla richiesta e restituisce il pacchetto.
I colori nei grafici precedenti e successivi mostrano esattamente, da un lato, ciò che si conosce e, dall'altro, ciò che se ne può dedurre:
- il verde è la conferma che Checkmk e l'host di destinazione possono comunicare sui livelli 3 e 7 reciprocamente. Le metriche, come il packet delay, vengono accumulate su questo livello.
- Il verde chiaro è il colore dell'accettazione, il che significa che il sistema di monitoraggio riconosce che questi livelli sono permeabili e che trasportano i pacchetti. Tuttavia, non sa se, ad esempio, sul livello 2 è stato utilizzato il vecchio protocollo Token Ring invece di Ethernet.
- Il rosso indica solo una speculazione: Se il livello 3 funziona, è stato soddisfatto un importante prerequisito affinché un server FTP possa funzionare su di esso, ma ciò non è affatto garantito.
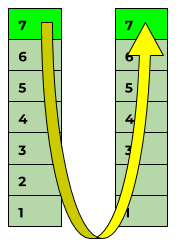
Il livello delle applicazioni
Il nome del livello 7, il cosiddetto "livello delle applicazioni", potrebbe facilmente dare l'impressione che sia proprio qui che si trovano le applicazioni con cui gli utenti lavorano. Ma non è così.
Il livello 7 è solo l'interfaccia di ingresso e di uscita delle applicazioni, che dipendono da esso. Purtroppo questo aspetto viene spesso frainteso.
Dato che il modello OSI esteso al livello 8 definisce l'uomo o l'utente, è necessario pensare a un livello intermedio su cui gira il software ("livello S").
E questo chiarisce: con i check di monitoraggio si controllano in realtà solo i prerequisiti per il livello software (= tutto compreso. Layer 7) - ma mai lo stato di questo stesso livello!
L'esperienza dell'utente finale
Qual è il ruolo effettivo di un amministratore?
- Sostituire i dischi rigidi?
- Monitorare le latenze?
- Installare aggiornamenti?
Sì e no. In realtà il suo compito è uno solo: garantire che gli utenti siano soddisfatti quando utilizzano i servizi e le applicazioni fornite, ovvero che abbiano una buona "esperienza utente finale". È su questo che l'IT viene misurato e giudicato. Tutti gli altri compiti di un amministratore sono solo una conseguenza di questa "missione":

Il fatto che il software in uso funzioni effettivamente rimane una questione di speculazioni, se l'amministratore non monitora direttamente il software, ma si limita a monitorare fino al livello 7. In questo scenario è possibile che il software funzioni come dovrebbe.
In questo scenario è possibile che quanto segue non venga rilevato:
- La qualità del servizio/prestazioni delle applicazioni con hosting esterno,
- qualsiasi deterioramento graduale dei tempi di avvio e di caricamento,
- crash apparentemente casuali dei programmi,
- errori di visualizzazione,
- problemi nelle catene di processi,
- dati obsoleti
E solo per citare alcuni possibili esempi.
Grazie a queste conoscenze di base, è ora possibile spiegare il significato del termine "End-to-End": l'obiettivo è spostare il monitoraggio nel modello OSI ancora più in alto, al limite dell'interazione tra computer e uomo. Al livello più alto, si potrebbe dire. Durante il monitoraggio end-to-end, questo livello viene testato dal punto di vista dell'utente.
Robot Framework
Quindi sì, fate (o lasciate fare) i test necessari. Robot Framework è uno dei migliori strumenti open source per i test automatizzati. Come un robot, passa attraverso gli stessi percorsi di un'applicazione più e più volte e può gestire qualsiasi tipo di applicazione, sia essa basata sul web o installata su Windows o Linux.
Tra l'altro, Robot Framework non è usato solo per testare il software. È anche molto adatto per la RPA (Robotic Process Automation). L'idea alla base è quella di automatizzare i flussi di lavoro che normalmente solo gli esseri umani possono eseguire, come ad esempio inserire stupidamente i dati in un software esistente che non ha un'interfaccia di importazione. Robot Framework si avvicina quindi molto all'immagine di un "robot software alla catena di montaggio"!
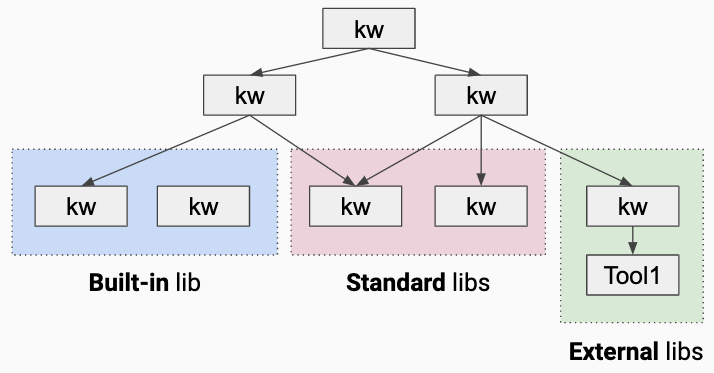
Se c'è una caratteristica che distingue Robot Framework da tutti gli altri strumenti di test, è certamente il suo approccio "basato sulle parole chiave". Robot è anche esteso con librerie che, ad esempio, tramite parole chiave speciali forniscono i metodi di test per Selenium, AutoIT, SAP, Sikuli ecc. Le parole chiave astraggono il codice di programma Python che sarebbe necessario per i test Selenium, ad esempio.
Le parole chiave possono essere annidate come le funzioni di un linguaggio di scripting e dotate di parametri di ingresso e di uscita. Certamente, la programmazione dei test in Python offre la massima libertà, ma restringe anche ai soli programmatori la cerchia di coloro in grado di scrivere i test. Poiché le parole chiave dei robot incapsulano e astraggono il codice Python, rendono molto più semplice la scrittura e la lettura/comprensione dei test.
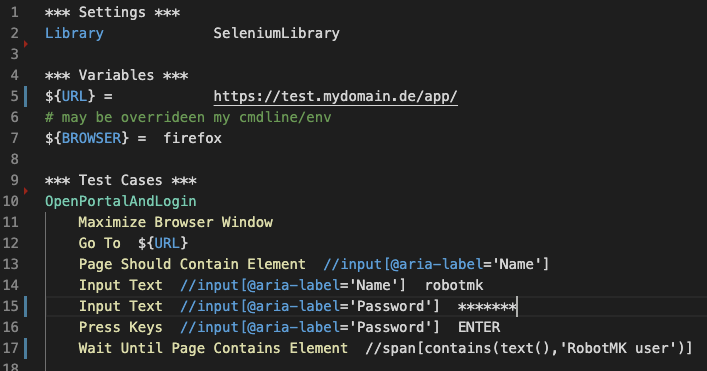
In questo estratto di un file robot, la libreria Selenium viene utilizzata per i test web (riga 2). Dopo aver definito due variabili nella sezione "Variabili", inizia la sezione "Casi di test". Il caso di test "OpenPortalAndLogi" esegue una serie di parole chiave della libreria Selenium per eseguire il login a un'applicazione web.
Quando si formulano i test, bisogna sempre verificare lo stato desiderato, come mostra la riga 17: il login è riuscito solo se esiste un elemento span che contiene il testo 'Robotmk user'.
L'integrazione di tali test robotici nel monitoraggio non era finora possibile, tuttavia in questo caso riguarda sia la regolare esecuzione che la valutazione dei risultati, perché gli errori funzionali o tecnici di performance dovrebbero essere segnalati in ogni caso.
Robotmk
"Robotmk" è un'estensione specifica per Checkmk che colma questa lacuna.

L'estensione è disponibile su Checkmk Exchange come MKP (MK-Package). Robotmk v1 è compatibile con tutte le versioni di Checkmk 1.6 e con Checkmk 2.0 in corso. Da Checkmk 2.3 Robotmk è integrato come nuovo componente aggiuntivo chiamato Checkmk Synthetic Monitoring. In questa sede parliamo di Robotmk v1.
Gli elementi centrali di Robotmk sono il plug-in e il Check. Il plug-in viene attivato in modo asincrono tramite l'agente Checkmk o esternamente tramite il task scheduler ed esegue i casi di test del robot sulla macchina di destinazione.
Il risultato di ogni test viene trasmesso attraverso l'output dell'agente al server Checkmk. Qui il check non solo valuta i tempi di esecuzione delle diverse sezioni di test, ma influenza anche la lunghezza e la forma dell'output. Un'altra regola definisce quali sezioni di test devono generare dati sulle prestazioni.
Utilizzando la Discovery Rule, è anche possibile creare servizi separati da singole sezioni di un test. Ciò è particolarmente utile, ad esempio, quando un robot esegue un test più volte utilizzando dati di test diversi, oppure quando diversi team devono essere avvisati separatamente in merito alle sezioni del test. Inoltre, per le suite di test è possibile fornire una sorta di "visualizzazione dei progressi in tempo reale" in Nagvis.
Tenendo presente il modello dei livelli OSI, diventa chiaro perché il "livello S", al di sopra del livello applicativo, non dovrebbe rimanere un punto cieco nel monitoraggio: dopo tutto, questo è il livello in cui l'utente interagisce con l'infrastruttura.
Con l'uso di un sistema di monitoraggio End-to-End basato su Robot Framework, è possibile monitorare la funzionalità e le prestazioni delle applicazioni in questo livello. Si tratta quindi di un potenziamento ideale di Checkmk, perché monitora ciò che l'utente vede.
Ulteriori vantaggi sono:
- Monitoraggio dell'interazione senza problemi tra tecnologie e catene funzionali.
- I test e le valutazioni cross-site (ad esempio, i rapporti SLA) creano una base chiara per la discussione e il processo decisionale.
- Un sistema di allarme precoce e proattivo per il funzionamento dell'applicazione. L'eliminazione proattiva dei problemi emergenti aumenta la disponibilità e garantisce immagine e fiducia nell'IT.
In breve, il monitoraggio end-to-end è il controllo sistematico dell'ultimo e più importante collegamento tra uomo e macchina.
Nel prossimo articolo del blog, come configurare Robotmk, vi mostreremo come è possibile configurare facilmente un test di Robot Framework e integrarlo in Checkmk utilizzando lo scheduler Robotmk in Checkmk 2.3.
Informazioni sull'autore:
Il monitoraggio è sempre stato una costante nei 20 anni di carriera di Simon nel settore IT: prima come amministratore, poi come consulente e dal 2018 nella sua società ELABIT GmbH, che ha fondato per concentrarsi sui test automatizzati delle applicazioni e sull'integrazione di tali test in Checkmk. La soluzione "Robotmk" è il risultato dei suoi sforzi ed è molto apprezzata dalla comunità Checkmk.
Quando non lavora in Checkmk come product manager, coordinando l'ulteriore sviluppo di Robotmk, aiuta i clienti di tutto il mondo a integrare il monitoraggio sintetico nel loro ambiente.