Wie Sie ein umfassendes SQL-Server-Monitoring einrichten
Heutzutage sind die meisten Desktop-, Mobil-, Cloud- und IoT-Applikationen, sowie andere Programme stark auf Datenbanken angewiesen. Aufgrund dieser Entwicklung sind SQL-Server-basierte Angebote, Kapazitäten und Auslastungen weiter gewachsen. Infolgedessen müssen Unternehmen sicherstellen, dass ihre Datensysteme die erforderlichen Performance-Anforderungen erfüllen.
In der Regel sind eine hohe Verfügbarkeit, effektive Services und eine schnelle Problembehebung essenziell für den reibungslosen Betrieb. Das Monitoring von SQL-Servern bietet die dafür nötigen Einblicke in die Gesundheit, die Leistung und in die Nutzungsmetriken.
TL;DR:
Das Monitoring von SQL-Servern ist entscheidend, um hohe Performance, Verfügbarkeit und eine effiziente Nutzung von Ressourcen sicherzustellen.
- Ein Monitoring bietet Einblicke in den Server-Zustand, deckt Leistungsengpässe auf und hilft, kostspielige Ausfallzeiten zu vermeiden.
- Wichtige Komponenten und Kennzahlen, von der CPU- und Speicherauslastung bis hin zu Abfrageleistung und Indizierung, unterstützen fundierte Optimierungsentscheidungen.
- Kontinuierliche Überwachung ermöglicht proaktive Planung für zukünftiges Wachstum und eine bedarfsgerechte Ressourcenzuweisung, während gleichzeitig Infrastrukturkosten reduziert werden.
- Leistungsstarke Lösungen wie Checkmk vereinfachen die Datenerfassung, liefern verwertbare Erkenntnisse und unterstützen Multi-Datenbank- sowie Cloud-Umgebungen.
Was ist ein SQL-Server?
SQL (Structured Query Language) ist eine Programmiersprache, die zur Verwaltung von relationalen Datenbanken verwendet wird. Es ist die Sprache, mit der die Anfragen geschrieben werden, um Daten aus relationalen Datenbanken zu bearbeiten oder abzurufen.
Ein SQL-Server ist das Tool oder die Software, wie zum Beispiel MSSQL von Microsoft, Oracle DB und PostgreSQL, eines relationalen Datenbankmanagementsystems (RDBMS), das Daten speichert, verarbeitet und verwaltet.
Außerdem führt der Server die SQL-Anfragen und -Befehle aus, um die Datenbank zu bearbeiten. In der Praxis hostet der SQL-Server die Datenbank und die SQL-Applikationen, während er auch alle Datenbankoperationen ausführt und verwaltet.
Was ist SQL-Server-Monitoring?
SQL-Server-Monitoring ist die kontinuierliche Erfassung und Analyse von Performance-, Ressourcenauslastungs-, Nutzungs- und Ereignismetriken eines SQL-Datenbank-Servers.
Neben der Identifizierung von Performance-Problemen, unzureichenden oder nicht ausgelasteten Ressourcen und anderen Problemen liefert es Erkenntnisse, die den IT-Teams beim Finetuning und Verbessern der Leistung helfen. Ein ideales und effektives Monitoring-Tool sollte Alerts senden, wenn die überwachten Metriken bestimmte Schwellwerte überschreiten.
Dadurch ist neben einer unmittelbaren Reaktion auf Probleme auch eine genaue Diagnose und Fehlerbehebung möglich. Darüber hinaus veranschaulicht sie die Ressourcennutzung und zeigt Trends auf, sodass die DBA-Teams planen und sich auf die Zukunft vorbereiten können.

Wer überwacht SQL-Server?
SQL-Server werden von internen Datenbankadministrator:innen (DBA), sowie internen oder externen Teams überwacht. Generell sollte jedes Unternehmen seine Datenbank-Server monitoren.
Unternehmen, die über keine ausreichenden internen Fachkenntnisse verfügen, können externe DBAs beauftragen, die sie bei Bedarf unterstützen.
Während die internen oder externen DBAs den reibungslosen Betrieb der Datenbankplattform gewährleisten, sollten auch andere Abteilungen einbezogen werden. Wenn es beispielsweise Probleme mit dem Netzwerk gibt, sollte sich das IT-Infrastruktur-Team darum kümmern.
Warum ist SQL-Server-Monitoring notwendig?
Das Monitoring eines jeden Servers ist ein Must-Do. Dementsprechend ist die Überwachung von SQL-Servern eine der wichtigsten Aktivitäten, um sich einen Überblick über die Datenbankplattform zu verschaffen. Sie liefert Erkenntnisse, die es den Teams ermöglichen, Verfügbarkeits- und Leistungsprobleme zu beheben und so kostspielige Systemausfälle zu verhindern. Auch wenn die Ziele des Monitorings für jedes Unternehmen unterschiedlich sind, gibt es doch einige wichtige Gründe, warum es unerlässlich ist.
Einblicke in die Server-Gesundheit
Gewinnen Sie wertvolle Einblicke in die Gesundheit, die Leistung und die Nutzungsmetriken des SQL-Servers. Das Monitoring der Ressourcenauslastung ermöglicht es den IT-Teams, Optimierungsmöglichkeiten zu erkennen und festzustellen, ob zusätzliche Ressourcen benötigt werden. Darüber hinaus können die Teams die Erkenntnisse zum Finetuning der SQL-Server nutzen, um die beste kosteneffektive Leistung zu erzielen.
Beim SQL-Server-Monitoring wird nicht nur überprüft, ob der Server optimal arbeitet, sondern auch, ob ungewöhnliche Aktivitäten stattfinden. Die Beobachtung der Funktionsweise bietet die Möglichkeit, die Leistung zu optimieren, etwaige Probleme zu beheben und Möglichkeiten zum Finetuning zu identifizieren. Zusätzlich hilft sie, zukünftige Bedürfnisse zu ermitteln.
Minimierung von Leistungsproblemen und Ausfallzeiten
Identifizieren und beheben Sie Engpässe und eine Vielzahl von Problemen, die die Performance beeinträchtigen oder zu einem Ausfall führen könnten. Die Teams können die Leistungsprobleme frühzeitig und schnell angehen. Darüber hinaus ermöglicht das SQL-Server-Monitoring den DBA- und IT-Teams, die Systeme zu optimieren, die Geschwindigkeit und die Benutzerfreundlichkeit zu verbessern und Ausfälle zu vermeiden.
Durch ein kontinuierliches Monitoring sind die Teams stets über den aktuellen Status des Servers informiert. Durch die Vermeidung größerer Probleme haben die Teams mehr Zeit, sich um wichtigere Aufgaben zu kümmern. Im Idealfall hilft Ihnen das Performance-Monitoring der SQL-Server-Datenbank, Ihren SQL-Server und Ihre Dienste reibungslos laufen zu lassen und gleichzeitig das Risiko unerwarteter Ausfallzeiten zu verringern.
Planung für zukünftiges Wachstum
Überwachen Sie die Ressourcennutzung und Kapazitätstrends zur Vorbereitung und Planung für die Zukunft. Neben der Performance kann das Monitoring auch andere nützliche Informationen liefern, die für die Planung künftiger Anforderungen bei wachsenden Datenbanken wichtig sind. So können beispielsweise Einblicke in eine Vielzahl von Metriken gewonnen werden, darunter Speichernutzung, Anfragen mit hoher Belastung, ressourcenintensive Anfragen, Buffering-Pool-Auslastung und andere Probleme, die sich auf die Leistung auswirken.
Reduzierung von Infrastrukturkosten
Das Monitoring ermöglicht es den Teams, die vorhandenen Ressourcen zu optimieren und so die Notwendigkeit von Investitionen in zusätzliche Hardware- und Software-Komponenten zu verringern. So können Sie die Infrastruktur optimal nutzen und verhindern, dass Sie in überflüssige Ressourcen investieren.
Optimierung der Wartezeit und Verbesserung der Service-Bereitstellung
Verbessern Sie die Antwortzeiten und die Leistung des SQL-Servers, indem Sie die Monitoring-Daten analysieren und zusätzlich korrigierende Maßnahmen ergreifen. Neben der Beobachtung der Antwortzeiten kann das Monitoring auch andere nützliche Informationen zur CPU, zum Speicher oder zu I/O-Kapazitätseinschränkungen, langen Wartezeiten und andere Metriken liefern. Dies gibt Ihnen die Möglichkeit, Fehler im Server zu beheben, ihn neu zu konfigurieren oder mehr Ressourcen hinzuzufügen und so die Antwortzeiten zu verbessern.
Im Idealfall ist das SQL-Server-Monitoring für alle Unternehmen von entscheidender Bedeutung, egal ob es sich um kleine, mittlere oder große Unternehmen handelt. Es bietet die Möglichkeiten, die Leistung von Datenbankabfragen zu verbessern, um so die Betriebszeit des Servers zu maximieren. Dadurch kann er Queries viel schneller verarbeiten und eine hohe Verfügbarkeit und Produktivität gewährleisten.
Was sollten Sie auf einem SQL-Server überwachen?
Das Verständnis der SQL-Server-Architektur, seiner Komponenten und deren Zusammenspiel ist unerlässlich, um zu wissen, was überwacht werden soll. Machen Sie sich bewusst, warum Sie eine bestimmte Metrik oder einen bestimmten Service monitoren wollen und was Ihr Ziel ist. Andernfalls konzentrieren Sie sich möglicherweise auf SQL-Server-Metriken und -Services, die sich nicht auf die Performance auswirken und somit nicht relevant für Sie sind.
Zu den wichtigsten Metriken auf der Software-Seite gehören u. a. Wartestatistiken, Indexfragmentierung, Buffer-Cache, Sicherheit usw. Darüber hinaus ist es wichtig, den Überblick über die Software-Versionen und den Wartungsbedarf zu behalten.
Die beste Strategie besteht darin, die Metriken zu ermitteln, die Ihnen helfen, Ihre individuellen Performance-Ziele zu erreichen. In der Regel werden einige allgemeine Metriken überwacht. Diese liefern ausreichende Informationen, um eine grundlegende Fehlersuche und Optimierung durchzuführen. Zu den häufig überwachten Metriken von SQL-Servern gehören Prozessor- und Speichernutzung, Festplattenaktivität und Netzwerkverkehr.
Bei komplexen Systemen und fortgeschrittener Fehlersuche kann es jedoch erforderlich sein, zusätzliche Metriken zu monitoren, um bestimmte Bereiche zu beobachten und die Ursache von Problemen zu finden.
Neben den Komponenten des SQL-Servers müssen Sie auch zusätzliche Metriken des Betriebssystems überwachen. Bei einem Windows-Server können Sie zum Beispiel Folgendes überwachen:
- Prozessorzeit, Prozessorauslastung und Länge der Prozessorwarteschlange,
- Netzwerknutzung, Netzwerkschnittstelle, Benutzerverbindungen usw.
- Paging, Lebenserwartung der Seiten, Lese- und Schreibvorgänge pro Sekunde, Lazy Writes usw. und
- gesamter Server-Speicher, Buffer-Cache-Trefferrate, Batch-Anforderungen usw.
Wichtige SQL-Server-Komponenten
Ein typischer SQL-Server besteht aus vier Hauptkomponenten, unabhängig davon, ob er On-Premises oder in der Cloud gehostet wird. Dazu gehören das Protokoll oder Netzwerk, die SQL-Server-Speicher-Engine, den Query Processor und das SQLOS (SQL-Betriebssystem).
Der Query Processor und die Speicher-Engine sind Teile der Datenbank-Engine, die eine der Hauptkomponenten eines SQL-Servers ist. In der Praxis ist die Hauptaufgabe der Datenbank-Engine die Erstellung und Ausführung von Stored Procedures, Triggern, Views und anderen Datenbankobjekten.
Protokoll und Netzwerk
Das Netzwerk und die zugehörigen Protokolle ermöglichen eine Verbindung mit dem SQL-Server. Die Geschwindigkeit dieser Verbindung wirkt sich auf die Gesamtleistung und das Benutzererlebnis aus. Daher ist es wichtig, den Netzwerkverkehr zu überwachen und Probleme, die die Performance beeinflussen, frühzeitig zu entdecken. Dies hilft, Anzeichen für ungewöhnlichen Datenverkehr und Engpässe zu erkennen.
Außerdem ist das Monitoring der Netzwerkprotokolle wichtig, um sicherzustellen, dass sie in Ordnung sind und die Leistung und Effizienz des SQL-Servers nicht beeinträchtigen.
Query Processor
Der Query Processor des SQL-Servers, der auch als relationale Engine bezeichnet wird, umfasst verschiedene Komponenten, die die Ausführung der Anfrage verwalten. Im Allgemeinen ruft er die Daten je nach Eingangsanfrage erst aus dem Storage ab, verarbeitet sie anschließend und stellt die Ergebnisse bereit.
Zu den Funktionen, die der Query Processor ausführt, gehören die Verwaltung des Speichers, des Buffers, der Task, der Anfrageverarbeitung und vieles mehr. Sie ist auch für das Sperren und Isolieren der Seiten, Tabellen und Zeilen verantwortlich, die die Anfrage benötigt.
Das Monitoring umfasst die Analyse der verarbeiteten Anfragen, der von ihnen verwendeten Ressourcen und der benötigten Zeit. Ein weiterer Bereich ist die Analyse der Query-Pläne, die der Server für die Ausführung verwendet. Zusätzlich muss auch die Rate der Erstellung von Ausführungsplänen analysiert werden.
Storage-Engine
Die Storage-Engine ist für die Dateiverwaltung, die Abwicklung von Transaktionen, den Zugriff auf verschiedene Datenbankobjekte und vieles mehr zuständig.
Das Monitoring der Engine stellt sicher, dass die Funktionen optimal laufen. Sollte die Engine nicht richtig oder wie erwartet funktionieren, können die DBA-Teams die Engpässe beheben. Zu den zu überwachenden Metriken gehören Dateizugriff, Storage-Kapazität, Verteilung und Leistung.
SQLOS – das SQL-Betriebssystem
SQLOS ist Bestandteil von MSSQL, das die verschiedene Aktivitäten zwischen dem SQL-Server und dem Betriebssystem koordiniert. Zu den typischen Funktionen gehören CPU-Planung, Speicherverwaltung, Hintergrunddienste, logische I/O und andere. Insbesondere die Hintergrundprozesse überwachen das System auf Deadlocks, überprüfen die Ressourcen und geben ungenutzten Speicher frei.
SQLOS-Monitoring ist wichtig, um eine optimale Ressourcennutzung zu gewährleisten, die Ressourcenauslastung im Blick zu haben und gegebenenfalls ein Upgrade einzuleiten. Dazu gehört die Beobachtung von Metriken wie CPU-Aktivität, Speicherzuweisung etc.
Welche Metriken sollten Sie auf einem SQL-Server überwachen?
SQL-Server-Monitoring liefert nützliche Erkenntnisse, die es Ihnen ermöglichen, fundierte Entscheidungen zu treffen und das Beste aus Ihrer Datenplattform herauszuholen. Es gibt zwar reichliche Metriken, aber Sie haben die Möglichkeit auszuwählen, was für Ihre spezielle Umgebung, Ihre Applikationen und Ihre Ziele wichtig ist.
Im Allgemeinen lassen sich die Metriken des SQL-Servers in die folgenden fünf Hauptkategorien einteilen:
- Transaktion,
- Buffer-Cache-Metriken,
- Lock-Metriken,
- Ressourcen und
- Indexierung.
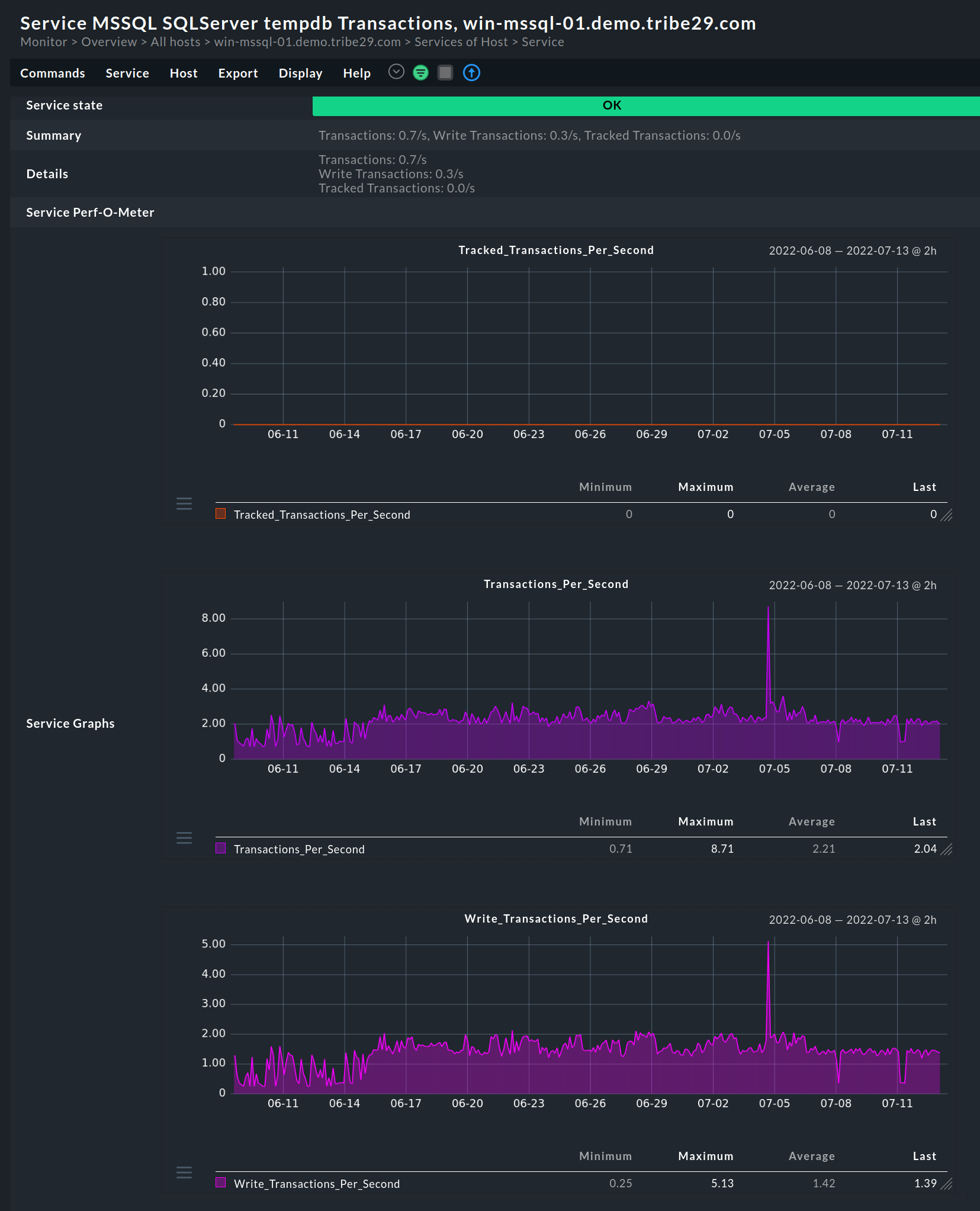
Transaktion-SQL-Metriken (T-SQL)
T-SQL ist eine Erweiterung der herkömmlichen SQL, die dem SQL-Server zusätzliche Funktionen hinzufügt. Sie interagiert mit relationalen Datenbanken und bietet Funktionen wie Transaktionskontrolle, Fehlerbehandlung, Zeilenverarbeitung und mehr. In der Praxis gibt es mehrere Metriken, die mit T-SQL überwacht werden können. Dazu gehören:
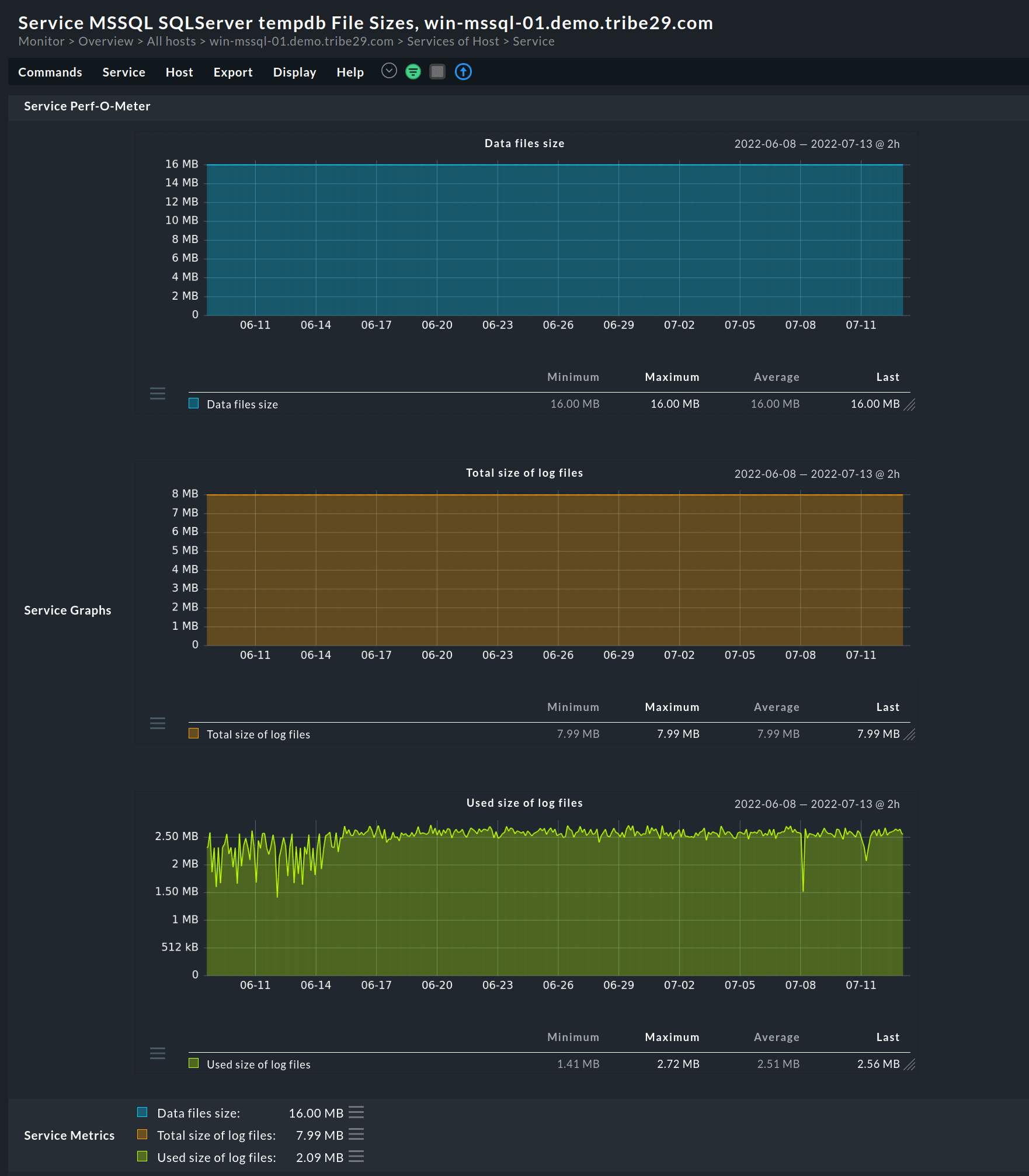
Batch-Anfragen pro Sekunde
Das Monitoring der Batch-Anfragen pro Sekunde bietet einen Überblick über die Datenbanknutzung. Es zeigt die Anzahl der Batch-Anfragen, die das Datenbankmodul pro Sekunde verarbeitet.
In der Praxis kann ein Batch eine einzelne oder mehrere SQL-Anweisungen umfassen, hat aber die gleiche Wirkung. Darüber hinaus wird auch ein Batch, der eine gespeicherte Prozedur aufruft, immer noch als einzelne Batch-Anfrage betrachtet.
Um einen besseren Einblick zu erhalten, ist es am besten, andere damit zusammenhängende Metriken wie beispielsweise die verstrichene Zeit oder die Speichernutzung zu erfassen.
SQL-Kompilierungen pro Sekunde
Die Kompilierungen pro Sekunde beziehen sich auf die Anzahl der Kompilierungen der SQL-Anfragen durch den Server in einer Sekunde. In der Praxis kompiliert und zwischenspeichert der SQL-Server die Anfragen vor der Ausführung. Im Idealfall sollte er eine Anfrage nur einmal kompilieren und sie dann in der Zukunft wiederverwenden oder referenzieren.
Das Kompilierung-Monitoring pro Sekunde zeigt, ob der Server nur einmal oder mehrmals auf die zwischengespeicherten Anfragen zurückgreift. Wenn er nur einmal darauf zugreift, bedeutet dies, dass er jede Batch-Anfrage kompiliert, und die Anzahl der Kompilierungen/Sekunde entspricht fast der Anzahl der Batch-Anfragen/Sekunde. Im Idealfall sollten die Kompilierungen pro Sekunde jedoch 10 % oder weniger als die Gesamtzahl der Batch-Anfragen pro Sekunde betragen.
SQL-Neukompilierungen pro Sekunde
SQL-Neukompilierungen pro Sekunde beziehen sich auf die Anzahl der Neukompilierungen der Anfragen durch den Server in einer Sekunde. Bei jedem Neustart des SQL-Servers oder bei Änderungen an den Datenbankdaten oder der Datenbankstruktur kann der bestehende Ausführungsplan ungültig werden.
In einem solchen Fall kompiliert der Server die Ausführungspläne neu. Während die Neukompilierung die Ausführung der T-SQL-Batches ermöglicht, erhalten Sie möglicherweise nicht die gleiche Performance wie es bei der vorherigen Kompilierung der Fall war.
Es ist daher wichtig, die Trends bei den Neukompilierungen pro Sekunde und mögliche Auswirkungen auf die Performance zu beobachten. Wenn die Leistung mit zunehmender Anzahl von Neukompilierungen pro Sekunde abnimmt, können Sie eine Anpassung der Schwellwert-Basislinie in Betracht ziehen, um die Rate zu senken.
Last elapsed time
Die last elapsed time gibt Aufschluss darüber, wie viel Zeit (in Mikrosekunden) der SQL-Server für die letzte Ausführung eines Plans oder einer Aufgabe benötigt hat. Normalerweise kompiliert der SQL-Server die T-SQL-Anfragen oder Anweisungen und zwischenspeichert sie dann als Ausführungspläne. Dadurch wird die Latenzzeit verringert und somit die Server-Leistung verbessert. Durch Cache-Monitoring lässt sich feststellen, wie lange der Server für die Ausführung der Anfragen benötigt.
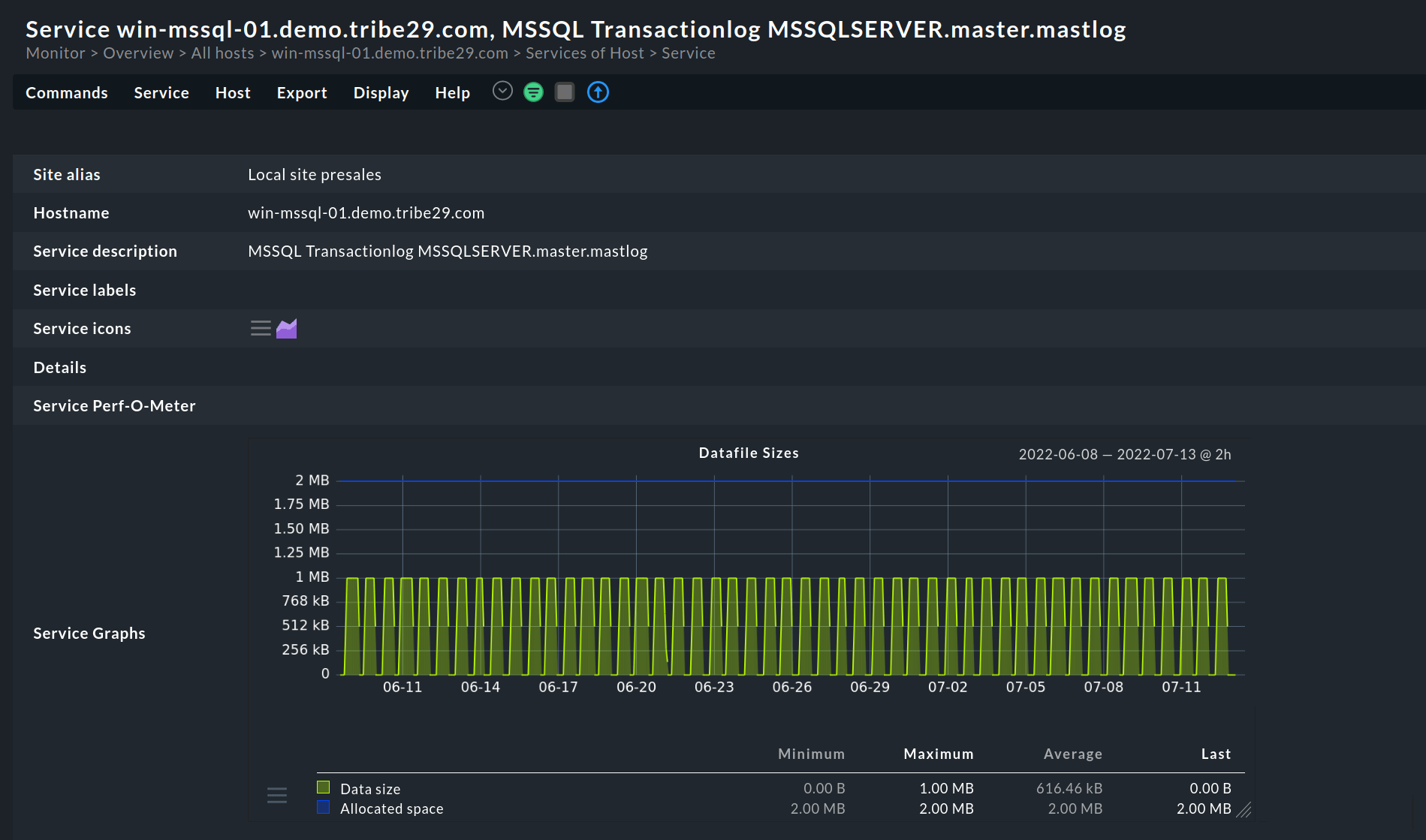
Buffer-Cache-Metriken
Bei der Ausführung von Anfragen finden die meisten Prozesse zwischen der Datenbank und dem Buffer-Cache statt. Das Buffer-Cache-Monitoring gibt daher Aufschluss über die Aktivitäten zwischen den beiden. Idealerweise sollte der SQL-Server so viele Lese-/Schreibvorgänge wie möglich im Speicher statt auf der langsamen Festplatte durchführen.
Zu den wichtigsten zu überwachenden Metriken gehören:
Trefferrate im Buffer-Cache
Die Buffer-Cache-Trefferrate vergleicht die Anzahl der Seiten, die der Buffer-Manager aus dem Cache zieht, mit der Anzahl der Seiten, die direkt von der Festplatte gezogen werden. Es ist wichtig, diese Kennzahl zu überwachen und Optimierungsbereiche zu ermitteln.
In der Regel kann eine niedrige Buffer-Cache-Quote zu einer hohen Latenz führen. Außerdem können Sie die Größe erhöhen, indem Sie mehr Speicher zuweisen. Obwohl es keine Standardkennzahl für das Buffer-Cache-Verhältnis gibt, wird ein Wert von mindestens 95 empfohlen, wenn eine hohe Leistung angestrebt wird. Aber auch ein Wert von 90 ist für eine Vielzahl von Applikationen geeignet.
Checkpoint-Pages pro Sekunde
Die Checkpoint-Pages pro Sekunde beziehen sich auf die Anzahl der Pages, die eine Checkpoint-Aktion pro Sekunde auf die Festplatte schreibt. Sobald eine Page geändert wird, verbleibt sie im Buffer-Cache als „Dirty Page“ bis zum Zeitpunkt des Checkpoints. Zum Zeitpunkt des Checkpoints verschiebt der Buffer-Manager dann alle „Dirty Pages“ auf das lokale Laufwerk, um Speicherplatz freizugeben.
Das Monitoring von Checkpoint-Pages pro Sekunde oder pro Rate, mit der der Buffer-Manager die Pages auf die Festplatte verschiebt, ist entscheidend bei der Ermittlung, ob die Ressourcen ausreichend sind oder nicht.
Page life expectancy
Die Page life expectancy zeigt, wie der Buffer-Manager die Lese- und Schreibvorgänge im Speicher durchführt. Sie zeigt z. B. die Zeit in Sekunden an, die eine Page ohne Referenz im Buffer-Cache verbleibt.
Nach dem Microsoft-Standard sollte die Page life expectancy (PLE) nicht weniger als 300 Sekunden pro 4 GB Arbeitsspeicher betragen, der dem Server zugewiesen ist. Mit mehr RAM können Sie einen höheren PLE-Schwellwert erreichen. Um den Wert zu berechnen, verwenden Sie die folgende Formel.
PLE-Schwellwert (Page Life Expectancy) = ((Bufferspeicherzuweisung (GB)) / 4) * 300
Wenn Sie dem SQL-Server zum Beispiel 10 GB RAM zuweisen, beträgt der PLE-Wert
PLE-Schwellwert = (10 / 4) * 300 = 750 Sekunden
In der Praxis leert der SQL-Server die Pages oft bei einem Checkpoint oder wenn mehr Platz im Buffer-Cache benötigt wird. Im letzteren Fall werden selten genutzte Seiten vom SQL-Server geleert.
Durch das Monitoring der Seitenanzahl, die pro Sekunde am Checkpoint gelöscht werden, können Sie feststellen, ob dies die Ursache für die hohe Fluktuation und damit die geringe Lebenserwartung ist.
Dies gibt Ihnen die Möglichkeit, eine Neukonfiguration vorzunehmen und eine optimale Einstellung zu erreichen. Wenn das Monitoring zeigt, dass die PLE-Werte mit zunehmender Arbeitslast sinken, deutet dies darauf hin, dass der Speicher nicht ausreicht und Sie eventuell mehr hinzufügen müssen.
Table-Ressourcen-Metriken
Es ist wichtig, SQL-Server-Tables zu überwachen und zu sehen, wie sie die verfügbaren Ressourcen nutzen. So lässt sich ermitteln, ob genügend Arbeitsspeicher, Storage und andere Ressourcen vorhanden sind.
Das Monitoring misst Metriken wie die Speichermenge in Kilobyte, die ein Table verwendet. Sie prüft auch den Platz, den die Daten oder Verzeichnisse eines Tables belegen.
Speicheroptimierte Tables
Ein SQL-Server verwendet speicheroptimierte Tables, die niedrige Latenzzeiten und einen hohen Transaktionsdurchsatz unterstützen. Im Allgemeinen verbessern speicheroptimierte Tables die Lese- und Schreibgeschwindigkeiten.
Das Monitoring der Erfüllungsrate von Anfragen aus den In-Memory-Tables sowie der Ressourcen, die der Prozess verbraucht, hilft Ihnen festzustellen, ob der Prozess optimal ist oder möglicherweise einige Anpassungen erfordert.
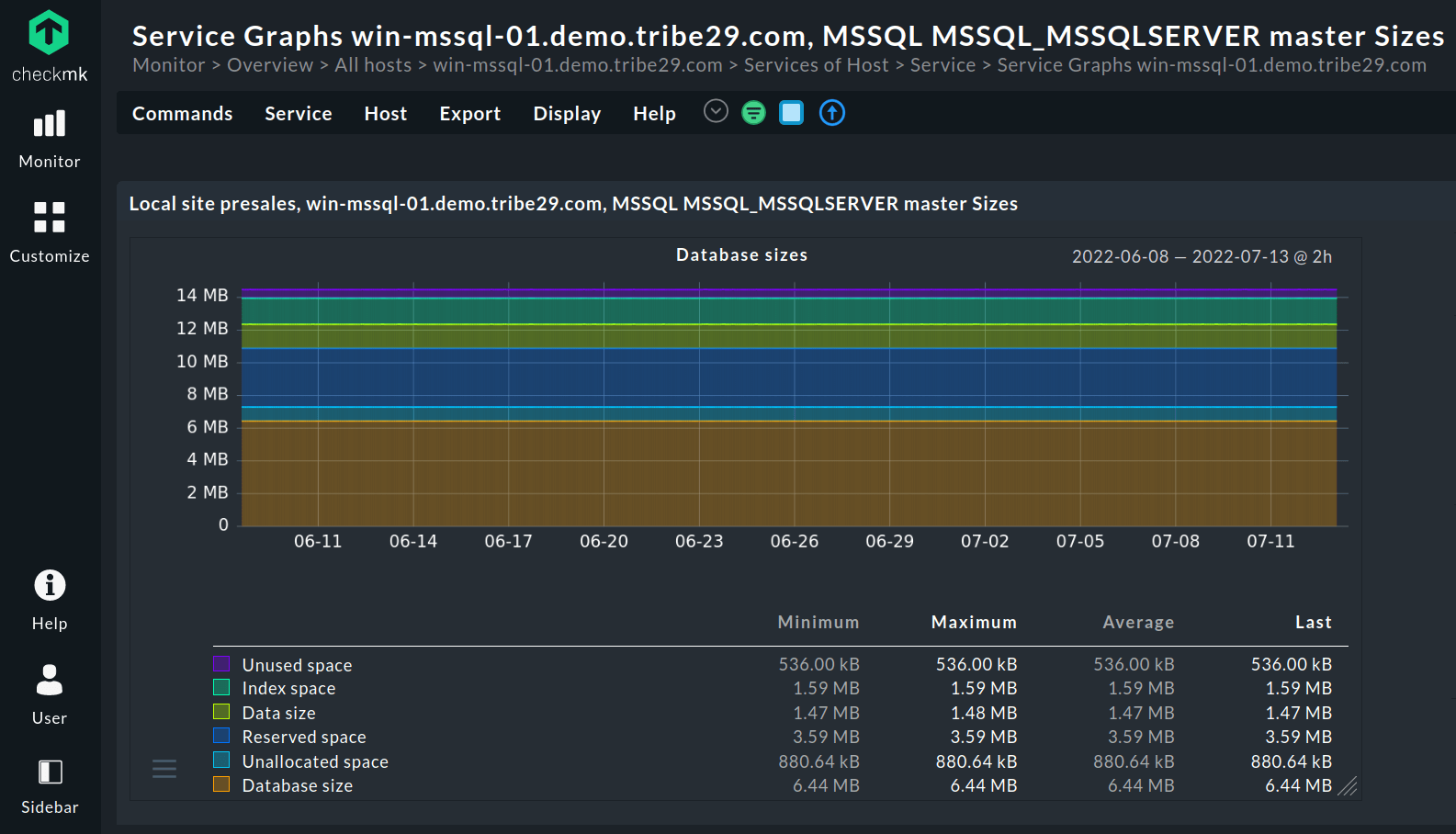
Festplattennutzung
Das Monitoring der Festplattennutzung hilft Ihnen, den Speicherplatz im Blick zu behalten und warnt Sie, wenn er knapp wird. So können Sie rechtzeitig Maßnahmen ergreifen und kostspielige Leistungsprobleme vermeiden. Zudem sollte die Überwachung die Menge an Speicherplatz ermitteln, die die Daten und Indexe in einer bestimmten Table belegen.
Ressourcenpool-Metriken
Der Ressourcenpool ist eine Darstellung der physischen Ressourcen des Servers wie CPU, Speicher, I/O und andere. Sie können die Ressourcenpools als virtuelle SQL-Server-Instanzen betrachten. Bei der Konfiguration der Ressourcenpools legen die Administratoren oft einige Grenzen für die Speicher-, Festplatten-I/O- und CPU-Ressourcen fest, die auf den Anforderungen Ihrer Applikationen basieren. Nach der Konfiguration müssen Sie sicherstellen, dass die Ressourcen effizient genutzt werden und dass die Benutzer:innen eine akzeptable Leistung erhalten.
Die beste Strategie besteht darin, die Ressourcen in den einzelnen Pools zu überwachen und bei Bedarf anzupassen.
CPU Usage %
Die prozentuale CPU-Auslastung ist der prozentuale Anteil der CPU des SQL-Servers, den alle Workloads in einem bestimmten Ressourcenpool verwenden. Sie können den minimalen und maximalen CPU-Prozentsatz für den jeweiligen Ressourcenpool angeben. Durch das Monitoring der CPU-Auslastung in Prozent können Sie Trends ermitteln. Sie sehen auch, wie sich die verschiedenen Einstellungen auf die Leistung auswirken, und können daher die Mindest-, Höchst- und harten Grenzwerte anpassen, um die Server-Leistung für bestimmte Aufgaben zu optimieren und anzupassen.
Disk-I/O-Operationen
Zu den Disk-I/O-Operationen gehören die Lese- und Schreibvorgänge auf der Festplatte; zwei der wichtigsten Metriken sind die Input- und Output-Zeit. Es ist wichtig, diese Metriken zu überwachen, da sie die Zeit angeben, die zum Lesen oder Schreiben von Daten in und aus dem Ressourcenpool benötigt wird. Der Festplattenlese-I/O pro Sekunde bezieht sich auf die Anzahl der Festplattenlesevorgänge, die innerhalb der letzten Sekunde pro Ressourcenpool durchgeführt wurden. Bei den Schreibvorgängen auf der Festplatte bezieht sich I/O auf die Schreibvorgänge auf der Festplatte.
Länge der Disk-Queue
Die Länge der Disk-Queue bezieht sich auf die Anzahl der Lese-/Schreibanforderungen in der Warteschlange für eine bestimmte Festplatte. Es ist wichtig, diese Kennzahl zu überwachen, da sie sich auf die Leistung auswirkt. Ist der Wert hoch, ist der Lese- und Schreibvorgang auf der Festplatte langsam, was zu einer hohen Latenz führt.
Eine mögliche Lösung wäre, mehr Festplattenkapazität hinzuzufügen, aber dies kann erst nach der Überprüfung anderer Metriken wie Datei- und Wartestatistiken erfolgen. Diese Metriken wirken sich ebenfalls auf die Lese- und Schreibgeschwindigkeiten aus.
Memory-Pages pro Sekunde
Die Memory-Pages pro Sekunde ist eine nützliche Metrik, deren Wert wesentlich bei der Ermittlung von Fehlern hilft, die die Performance beeinträchtigen könnten. Das Monitoring ist entscheidend für die Feststellung sämtlicher Memory-Probleme. Ein hoher Wert deutet auf eine hohe Auslagerungsrate des Arbeitsspeichers auf und von der Festplatte hin.
Latch-Wartezeit
Ein SQL-Server verwendet Latches, um die In-Memory-Daten zu schützen. Sie helfen auch dabei, die Integrität der Daten in den verschiedenen gemeinsam genutzten Ressourcen zu erhalten. Im Allgemeinen gibt es Buffer- und Non-Buffer-Latches. Das Monitoring der Latches ermöglicht es Ihnen, die Statistiken einzusehen und die Ursachen für Verzögerungen zu ermitteln.
Wenn das I/O-System nicht in der Lage ist, mit der Rate der aktiven Anfragen über einen längeren Zeitraum Schritt zu halten, kommt es zu einer Wartezeit von Latches. In einer solchen Situation dauert es auch länger, die Daten vom Laufwerk zu holen und in den Speicher zu kopieren.
Metriken für Locks
Bei jeder Anfrage einer Zeile, Page oder Tables eines Datensatzes aktivieren die Systeme einen Lock, der verhindert, dass andere Prozesse die bearbeiteten Daten ändern.
Lock-Verzögerungen pro Sekunde
Eine hohe Anzahl von Verzögerungen pro Sekunde bedeutet, dass das System längere Zeit auf die Freigabe warten muss, was zu Performance-Problemen führen kann.
Eine hohe Anzahl von Locks ist zwar ein Anzeichen für ein Problem, doch hängt dies von der Server-Kapazität ab. Ein Server, der etwa 100 Anfragen pro Sekunde verarbeitet, wird weniger Locks haben als ein Server mit 2 Millionen Updates pro Sekunde.
Durchschnittliche Wartezeit von Locks
Ressourcen, auf die mehrere Personen zugreifen, werden in der Regel vom SQL-Server gesperrt, um Fehllesungen zu vermeiden. Um zu verhindern, dass man zu lange auf den Zugriff auf die Ressourcen wartet, sollte die durchschnittliche Wartezeit für Locks so kurz wie möglich sein.
Das Monitoring der durchschnittlichen Wartezeiten von Locks bietet die Möglichkeit, Verzögerungen zu erkennen und festzustellen, welche Anfragen länger brauchen, um Locks freizugeben.
Indexierung
Die Indexierung erhöht die Geschwindigkeit der Suche nach Daten in der Datenbank. Mit zunehmender Datenmenge wächst der Index, und der SQL-Server kann ihn durch Aufteilung effizienter machen. Dies erhöht jedoch den Ressourcenverbrauch und kann zu Ineffizienzen führen.
Index-Monitoring ermöglicht es den Teams, die indexbezogenen Metriken genau zu beobachten und so die notwendigen Maßnahmen zu ergreifen, um eine effiziente Anfrageverarbeitung zu gewährleisten.
Zu überwachende Metriken
Page-Splits pro Sekunde
Beim Monitoring wird die Anzahl der Page-Splits pro Sekunde überprüft, die aufgrund einer Zunahme der Datenmenge auftreten. Normalerweise werden die Indexe, genau wie die Daten, auf Pages gespeichert. Wenn die Daten ansteigen, werden auch die Indexe größer. Wenn eine Page jedoch zu voll wird, erstellt der SQL-Server eine weitere Index-Page und verschiebt einige Zeilen von der vollen Page auf die neue Page.
Da dieser Prozess eine beträchtliche Menge an Ressourcen verbrauchen kann, ist es wichtig ihn im Auge zu behalten und Maßnahmen zu ergreifen, wenn die Anzahl der Page-Splits pro Sekunde zu hoch ist. Leider können zu viele Page-Splits zu einer Fragmentierung führen und dadurch die Leistung stark beeinträchtigen.
Fragmentation %
Von Fragmentierung spricht man, wenn die Datenreihenfolge im Index von der Reihenfolge abweicht, in der die Daten auf der Festplatte gespeichert sind. Im Allgemeinen führt dies zu einer langsamen Performance, da das System mehr Zeit benötigt, um den Index und die entsprechenden Daten abzugleichen.
Zu den Ursachen der Fragmentierung gehören wachsende Daten, Page-Splits und Änderungen im Index nach dem Aktualisieren, Einfügen und Löschen von Einträgen.
Das Monitoring ist eine Möglichkeit, das Ausmaß der Fragmentierung zu bestimmen, und eine nützliche Metrik ist Fragmentation %. Sie bezieht sich auf den Prozentsatz der Auftragsseiten im Index. Wenn die Fragmentierung hoch ist, verlangsamt sich die Leistung, und Sie können dies nur durch einen Neuaufbau des Indexes beheben.
Verbindungsmetriken
Die Aufrechterhaltung einer zuverlässigen Client-Verbindung ist entscheidend für die ordnungsgemäße Ausführung von Anfragen. Sie sollten daher die Verbindungen überwachen und sich mit ihnen befassen, um eine zuverlässige Performance und Verfügbarkeit zu gewährleisten.
Benutzerverbindungen
Die Metrik bezieht sich auf die Anzahl der Personen, die zum Zeitpunkt der Messung erfolgreich mit dem SQL-Server verbunden waren. Das Monitoring der Verbindungen und die Korrelation mit anderen Metriken bietet Ihnen die Möglichkeit, Optimierungsbereiche zu entdecken.
Wie können Sie mit dem Monitoring Ihrer SQL Server-Umgebung beginnen?
Im Idealfall ist die beste und effektivste Vorgehensweise die Verwendung einer zuverlässigen Monitoring-Lösung. Damit haben Sie alles an einem Ort und alle notwendigen Einblicke. Andernfalls müssen Sie sich auf jedem System anmelden und die gewünschten Informationen manuell überprüfen.
Sie können zwar einige Probleme manuell überwachen, dies ist dennoch mühsam und ineffektiv, vor allem, wenn Sie viele SQL-Server in Ihrer Umgebung haben.
Wenn Sie ein Monitoring-Tool verwenden, brauchen Sie eine gute Strategie. Dazu müssen Sie einige bewährte Schritte befolgen.
Schritt 1: Ermitteln Sie Ihre SQL-Server
Ermitteln Sie alle SQL-Server, die Sie überwachen müssen. Das hilft Ihnen, die Anzahl und den physischen Standort der SQL-Server in Ihrer Umgebung zu bestimmen, insbesondere wenn Sie neu in der Umgebung sind.
Schritt 2: Verschaffen Sie sich einen Überblick über Ihre SQL-Server-Umgebung
Erstellen Sie eine Übersicht über alle wesentlichen Anlagen und Komponenten Ihres SQL-Server-Ökosystems. Eine der besten Praktiken besteht darin, alle Komponenten der SQL-Infrastruktur zu identifizieren und sie zu dokumentieren.
Dadurch vereinfachen Sie sich das Monitoring und Management Ihrer Umgebung und die Erfassung aller Assets und Komponenten.
Schritt 3: Bestimmen Sie die zu überwachenden Metriken
Legen Sie die SQL-Server-Metriken fest, die Sie überwachen wollen. In der Regel verfügt die Datenbankplattform über so viele Metriken, dass Sie eine Vielzahl von Schlüsselbereichen im gesamten Ökosystem verfolgen und Einblicke gewinnen können.
Idealerweise sollten Sie die wichtigsten Hardware- und Software-Ressourcen sowie andere wichtige Performance-Metriken monitoren. Zu den typischen Komponenten gehören die CPU, der Arbeitsspeicher, die Speicherlaufwerke, das Netzwerk und andere. Darüber hinaus hilft es Ihnen, die Kapazität zu überwachen, damit Sie zukünftige Upgrades planen können.
Neben der Hardware müssen Sie auch die Software-Konfigurationen und deren Auswirkungen auf die Performance verfolgen.
Schritt 4: Wählen Sie ein effektives Monitoring-Tool
Suchen Sie nach Tools, die Ihren Monitoring-Zielen am besten entsprechen. Da sich die SQL-Server-Implementierungen bei jedem Unternehmen unterscheiden, ist es wichtig, eine Monitoring-Strategie festzulegen. Dabei sollten Sie alle Schlüsselkomponenten, die sich direkt auf die Leistung Ihrer Datenbank auswirken, optimal erfassen können.
Schritt 5: Starten Sie mit dem Monitoring und passen Sie Ihre Strategie an
Setzen Sie Ihre Strategie mit dem gewählten Monitoring-Tool um und ermitteln Sie den Zustand Ihrer Datenbankplattformen. Überwachen Sie alle wichtigen Metriken, die sich auf die Gesundheit und die Performance des SQL-Servers auswirken.
Evaluieren Sie Ihre Strategie zum Monitoring des SQL-Servers und passen Sie sie gegebenenfalls an, um ihre Effizienz zu verbessern. Abhängig von Ihren Konfigurationen, erhalten Sie möglicherweise eine Vielzahl von Alerts, von denen jedoch einige Fehlalarme, Duplikate oder andere sind.
Ein Überfluss an Alerts führt schließlich zu langsamen Reaktionszeiten und verhindert, dass Sie die wichtigsten Probleme schnell beseitigen können.
Was ist die beste Monitoring-Software?
Es ist eine gute Vorgehensweise, effektive Tools zum Monitoring Ihrer SQL-Server einzusetzen, die Sie nur bei Problemen benachrichtigen. Eine gute Monitoring-Lösung sollte Sie zum Beispiel alarmieren, wenn Ressourcen wie CPU, RAM und Festplatte übermäßig beansprucht werden oder wenn es Probleme mit anderen Performance-Metriken gibt.
Es ist wichtig, dass die Lösung eine präzise Überwachung mit minimalem Aufwand bietet und eine Vielzahl von Datenbanken und Umgebungen unterstützt. Wenn ein Monitoring-Tool zu zeitaufwändig in der Anwendung ist, wirkt sich das auch auf die Arbeit der DBA-Teams aus, was wiederum zu Lücken beim Datenbank-Monitoring führt.
Eines der besten SQL-Monitoring-Tools ist Checkmk. Das Tool verfügt über eine Vielzahl von Plugins, die das Sammeln und Analysieren von Metrikdaten sehr einfach macht.
Außerdem ist Checkmk einfach und flexibel einzurichten und unterstützt unter anderem Datenbanken wie Microsoft SQL, Oracle Database, PostgreSQL, MariaDB und IBM DB2. Mit nur wenigen Klicks können Sie ein umfassendes Monitoring für Ihre SQL-Server einrichten und Ihre SQL-Server mit Checkmk überwachen.
Alle notwendigen Plugins sind über die grafische Benutzeroberfläche von Checkmk aufrufbar und ebenfalls mit nur wenigen Klicks installiert.
Darüber hinaus ist Checkmk problemlos skalierbar und für alle Arten von Unternehmen geeignet. Swisscom beispielsweise überwacht mit Checkmk problemlos riesige Oracle-Datenbanken mit mehreren tausend Services pro Host.
Auch Datenbanken in der Cloud, etwa AWS RDS, lassen sich mit Checkmk problemlos monitoren. Monitoring-Integrationen in NoSQL-Datenbanken wie Redis, MongoDB oder Couchbase sind ebenfalls verfügbar.
Checkmk ist auch für den teamübergreifenden Einsatz geeignet und bietet DBA-Teams dank der tiefen Prometheus-Integration einen einfachen Zugang zur DevOps-Welt. Gleichzeitig profitieren auch die Entwickler von den Daten aus Checkmk und können die Interaktionen von Datenbanken und Applikationen überwachen.
Häufige Probleme beim SQL-Server-Monitoring
DIY oder Eigenbaulösungen mögen als günstige und preiswerte Alternativen für das Server-Monitoring erscheinen. Jedoch können sie sich oftmals als ineffektiv, zeitaufwendig und auf lange Sicht kostspielig erweisen.
Einige Unternehmen entscheiden sich für selbst entwickelte oder manuelle Monitoring-Lösungen, um Kosten zu sparen. Dieser Ansatz ist allerdings ineffektiv, vor allem, wenn es viele Instanzen gibt. Es ist außerdem nicht möglich, SQL-Server, die über lokale, Cloud- oder Hybrid-Infrastrukturen verteilt sind, vollständig zu überwachen.
Das Fehlen eines geeigneten SQL-Server-Monitoring-Tools verhindert den effizienten Betrieb des Datenbanksystems. Insbesondere die IT-Teams können die Bereitstellung neuer Prozesse verzögern, vor allem, wenn sie die meiste Zeit mit manuellen, zeitaufwendigen Aufgaben verbringen.
Aufgrund der Ineffektivität werden sich die DBAs damit abmühen, die Ursache von Problemen zu finden, anstatt die Zeit sinnvoll zu nutzen.
Das Problem mit DIY-Lösungen zum SQL-Server-Monitoring
Die Implementierung einer DIY-Lösung für das SQL-Server-Monitoring mag zwar attraktiv erscheinen und eine Möglichkeit zur Kostenreduzierung darstellen, birgt jedoch verschiedene Herausforderungen. So kann es sein, dass sie langfristig nicht den gewünschten Erfolg bringt. Im Folgenden finden Sie einige der Probleme, auf die Sie wahrscheinlich stoßen werden.
Sammelt zu viele Daten
Einige Tools sammeln zu viele Daten, darunter auch Informationen, die nichts mit der SQL-Server-Performance zu tun haben. Die Analyse dieser Daten dauert länger, was die Monitoring-Effizienz beeinträchtigt. Ein ideales Tool sollte schnell sein und gleichzeitig relevante Informationen sowie vorzugsweise umsetzbare Erkenntnisse liefern.
Erfasst unzureichende Informationen
Sammlung unzureichender Informationen: Auch ein Tool, das nur wenige Informationen liefert, ist ungeeignet und ineffektiv. Ohne angemessene Informationen ist es für die DBA-Teams schwierig, die richtigen oder effektiven Schlussfolgerungen zu ziehen.
Außerdem könnten sie unnötig viel Zeit und Mühe aufwenden, um ein kleines Problem zu lösen, das eigentlich nur geringe Investitionen erfordert hätte.
Erhöht den Verwaltungsaufwand
Das Monitoring erhöht den Verwaltungsaufwand. Es verursacht zu viele unnötige Alerts, denen das DBA-Team nachgehen muss und dadurch viel Zeit verschenkt. Bei präzisen Benachrichtigungen könnte es diese Zeit für andere Aufgaben nutzen.
Benötigt mehr Ressourcen
Obwohl die Auswirkungen des Monitoring-Tools auf die SQL-Server-Performance vernachlässigbar sind, gibt es Fälle, in denen der Ressourcenverbrauch hoch ist. Die Auswirkungen hängen weitgehend von der Umgebung ab, etwa ob der Server intern, in der Cloud oder in einer hybriden IT-Infrastruktur gehostet wird. Bei einem Cloud-basierten Server kann das Monitoring-Tool beispielsweise eine erhebliche Bandbreite verbrauchen.
Der Netzwerkverkehr des Tools kann mit den eigentlichen Datenbankapplikationen konkurrieren und so die Reaktionsgeschwindigkeit verringern. Ebenso kann ein Tool, das mehr CPU und Speicher benötigt, die Performance beeinträchtigen. Dies ist in der Regel eine Herausforderung, wenn nur begrenzte Ressourcen vorhanden sind.
Fehlende Dokumentation
Neben dem Zeitaufwand für die Entwicklung des internen Monitoring-Tools können auch die Wartungskosten und andere Herausforderungen hoch sein. Hausinterne Lösungen sind anfällig für viele Probleme, darunter fehlende Dokumentation, Angestellte, die das Unternehmen verlassen, Skalierungsprobleme und vieles mehr.
Ohne Dokumentation beispielsweise ist es nicht möglich, festzustellen, welcher Angestellte an einem bestimmten Teil der Lösung gearbeitet hat. Und wenn die Programmierer das Unternehmen verlassen, wird die Wartung der Lösung zu einer Herausforderung oder sehr teuer.
Abschließende Überlegungen zum SQL-Server-Monitoring
Bei heutigen Applikationen, wie z. B. Mobil-, industriellen und Desktop-Applikationen, sind Datenbanken eine kritische Komponente. Die Sicherstellung einer hohen Effizienz und Verfügbarkeit ist daher von entscheidender Bedeutung für eine hervorragende Benutzererfahrung und Geschäftsabläufe.
Schlecht funktionierende SQL-Server beeinträchtigen nicht nur die Effizienz der unternehmensinternen Abläufe, sondern auch die externen Kundendienste.
Eine der besten Möglichkeiten, die Performance im Auge zu behalten, Probleme zu erkennen und DBAs die Möglichkeit zu geben, schnelle Korrekturen vorzunehmen, ist die Implementierung eines effektiven SQL-Server-Monitorings.
Um ein kontinuierliches SQL-Server-Monitoring zu erreichen, benötigen Sie jedoch ein effektives Tool, das alle relevanten Metriken erfasst und Ihnen verwertbare Erkenntnisse liefert.
Im Idealfall ermöglicht die Überwachung den IT-Teams, kritische Performance-Probleme auf dem Server schnell zu erkennen. Ein effektives Tool bietet insbesondere die Möglichkeit, eine Vielzahl von Leistungsmetriken aufzuschlüsseln und zu analysieren.
FAQ
Wie kann ich Microsoft SQL Server überwachen?
Microsoft SQL Server kann man mit Monitoring-Lösungen wie Checkmk monitoren. Das umfassende und in hohem Maße anpassbare Tool kann eine Vielzahl von Metriken überwachen, wertvolle Daten sammeln und verwertbare Erkenntnisse liefern. Da Anforderungen an das Monitoring in jeder Umgebung und bei jeder Applikation unterschiedlich sind, können Sie Checkmk speziell an die Anforderungen in Ihrer IT-Infrastruktur anpassen.
Die Software hilft Ihnen, präzise Alerts festzulegen, die Performance zu visualisieren, Probleme zu erkennen und Ihre Ressourcen zu optimieren, um den besten ROI zu erzielen. Es ermöglicht Ihnen auch, bestehende und potenzielle Leistungsrisiken zu verwalten.
Wie starte ich den SQL-Aktivitätsmonitor?
Der Aktivitätsmonitor kann auf verschiedene Weise gestartet werden. Dazu gehören:
- Klicken Sie auf das Symbol des Aktivitätsmonitors in der Symbolleiste von SQL Server Management Studio.
- Gehen Sie zur Objektsuche und klicken Sie mit der rechten Maustaste auf die SQL-Server-Instanz und wählen Sie den Aktivitätsmonitor.
- Verwendung der Tastenkombination Ctrl+Alt+A
- Einstellen, dass der Aktivitätsmonitor sich automatisch öffnet, wenn SQL Server Management Studio gestartet wird.