Elasticsearch-Monitoring mit Checkmk
 on 18.06.2020
on 18.06.2020
Ob auf den eigenen Systemen oder in der Cloud: Applikationen generieren eine große Menge an Daten – jeden Tag, jede Stunde und jede Minute. Wir sprechen nicht mehr von Gigabytes oder Terabytes, sondern eher von Petabytes, Exabytes und Zettabytes. Gleichzeitig suchen wir nach Wegen, um Informationen möglichst schnell und effizient zu finden. Bei der Menge an Daten benötigt man dafür vor allem skalierbare und flexible Lösungen.
Unabhängig von proprietären Lösungen wie Splunk oder Solr gibt es für einen solchen Anwendungsfall natürlich noch Elasticsearch. Elasticsearch ist eine der beliebtesten Open-Source-Suchmaschinen. Sie ist in der Lage, große Datenmengen zu durchforsten, bietet jedoch keinen wirklichen detaillierten Einblick in den aktuellen Zustand der Daten – zumindest nicht über eine graphische Benutzeroberfläche. Hierfür gibt es zwar noch Kibana als optionalen Bestandteil eines Elastic-Stacks, aber vielleicht betreiben Sie ja keinen vollständigen Elastic-Stack – der Elasticsearch, Logstash und Kibana umfasst – sondern nur die Suchmaschine allein.
Um alle Ereignisse rund um Ihre Elasticsearch-Installation überwachen zu können, benötigen Sie nicht das Komplettpaket. Es ist möglich, jede beliebige Monitoring-Lösung zu verwenden, um die Suchmaschine und ihre Performance überwachen zu können. In diesem Blogpost wollen wir die grundlegenden Konzepte von Elasticsearch erklären und Vorschläge machen, worauf Sie beim Monitoring Ihrer Elasticsearch-Instanz achten sollten. Anschließend zeigen wir, wie Sie Checkmk konfigurieren, um Elasticsearch und seine Leistungsparameter überwachen zu können.
TL;DR:
Der Artikel erklärt die Grundlagen von Elasticsearch und zeigt, worauf Sie beim Monitoring achten sollten – inklusive einer Anleitung, wie Sie Elasticsearch mit Checkmk überwachen.
- Für das Monitoring von Elasticsearch eignet sich nahezu jede beliebige Monitoring-Lösung.
- Wichtige Monitoring-Aspekte für Elasticsearch:
- Anzahl der Nodes und speziell der Daten-Nodes
- Offene bzw. unerledigte Cluster-Aufgaben
- Node-Metriken wie CPU-Auslastung, Arbeitsspeicher, Dateideskriptoren usw.
- Schritt-für-Schritt wird gezeigt, wie Sie diese Werte mit Checkmk erfassen und zur Leistungsüberwachung nutzen.
Wie funktioniert Elasticsearch?
Ealsticsearch ist eine verteilte RESTful-Such- und -Analyse-Engine, die auf Apache Lucene basiert und eine schnelle Volltext-Suchmaschine für alle Arten von strukturieren und unstrukturierten Daten bietet, etwa Log-Dateien, Finanzinformationen, geographische Daten etc. Sie ist außerdem in Java implementiert. Zusammen mit Logstash (Datenerfassung), Beats (Daten-Shipper) und Kibana (Visualisierung) bildet Elasticsearch einen sogenannten Elastic-Stack, früher auch ELK-Stack genannt.
Elasticsearch ist nicht nur schnell, sondern auch skalierbar. Sie können jederzeit Server (sogenannte Nodes) zu Ihrem Cluster hinzufügen, um dessen Kapazität zu erhöhen. Das funktioniert, weil es sich beim Elasticsearch-Index in Wirklichkeit nur um eine logische Gruppierung von einem oder mehreren physischen „Shards“ (Scherben) handelt, wobei jede „Scherbe“ ein in sich geschlossener Index ist. Durch die Verteilung der Dokumente auf mehrere Shards und der anschließenden Verteilung der Shards über mehrere Nodes hinweg, gewährleistet Elasticsearch Redundanz. Darüber hinaus migriert die Software automatisch Shards, wenn der Cluster wächst oder schrumpft.
Da die Suchmaschine oft in geschäftskritischen Bereichen zum Einsatz kommt, ist die Überwachung ihres Status und ihrer Leistung unerlässlich. Administratoren sollten stets über ihre Elasticsearch-Cluster, -Nodes, -Indizes und -Shards informiert sein. Stellen sie Anomalien fest, müssen sie möglicherweise Konfigurationen anpassen oder zusätzliche Ressourcen hinzufügen. Natürlich wäre es ideal, wenn alle Änderungen in der Konfiguration sofort in der Monitoring-Lösung sichtbar sind.
Dinge, die ins Elasticsearch-Monitoring gehören
Aber was sollten Sie bei Elasticsearch überhaupt überwachen? Wir haben bereits Cluster, Nodes, Indizes und Shards erwähnt. Mehrere Nodes bilden einen Cluster. Die Nodes, die zusammen arbeiten, erhöhen zudem die Geschwindigkeit und sorgen für Redundanz. Fällt ein Node aus, sinkt die Gesamtleistung des gesamten Clusters. Daher sollte man sicherstellen, dass alle Nodes einwandfrei funktionieren. Die Bestimmung der Anzahl der arbeitenden Nodes sowie die Anzahl der Daten-Nodes, die nur für die Ausführung der eigentlichen Suchanfragen zuständig sind, ist nur ein Aspekt bei der Überwachung von Elasticsearch.
Sollte ein Cluster Aufgaben nur langsam verarbeiten oder viele Tasks noch unerledigt sein, könnte dies ein Hinweis auf eine falsche Konfiguration sein oder einen größeren Bedarf an Ressourcen signalisieren. Daher ist es absolut sinnvoll, Zeitüberschreitungen zu vermeiden und auf Leerlaufzeiten und ausbleibende Aufgaben zu achten.
Die Dinge, die Sie in Ihrem Elasticsearch-Cluster immer im Blick haben sollten, sind also:
- Anzahl der Nodes,
- Anzahl der Daten-Nodes,
- offene Aufgaben und
- detaillierte Informationen über Nodes, etwa CPU-Auslastung, Dateideskriptoren, Arbeitsspeicher etc.
Um den Suchprozess zu beschleunigen, erstellt Elasticsearch einen Index. Wenn dieser Index immer größer wird, kann die Software ihn in mehrere Teile „zersplittern“. Diese „Scherben“ (Shades) verteilt Elasticsearch nun auf mehrere Nodes in einem Cluster. Darüber hinaus kann jede Scherbe auch Replikate haben, wobei jeder Node, der eine oder mehrere Shards hostet, als Koordinator fungiert, um alle Operationen an die richtige(n) Shard(s) zu delegieren. In der Regel speichert die Software ähnliche Daten im gleichen Index, der aus einer oder mehreren primären Shards und optionalen Replikaten besteht. Bei der Überwachung geht es darum, die Anzahl der Shards sowie ihren Zustand im Auge zu behalten, da es nicht möglich ist, die Anzahl der Primär-Shards zu verändern, sobald ein Index erstellt wurde.
Es ist beim Elasticsearch-Monitoring also sinnvoll, folgende Aspekte bezüglich der Shards zu überwachen:
- aktive Shards,
- aktive primäre Shards,
- aktive Shards in Prozent,
- verspätete, nicht zugeordnete Shards,
- nicht zugeordnete Shards,
- laufende Informationsanfragen zu Shards und
- verlagerte Shards.
Darüber hinaus sollten Sie folgende Dinge über ihre Indizes im Blick behalten:
- Dokumentenanzahl (und -wachstum pro Minute),
- Größe (Wachstum pro Minute),
- Gesamtzahl der Dokumente und
- Gesamtgröße.
Wie lässt sich Elasticsearch mit Checkmk monitoren?
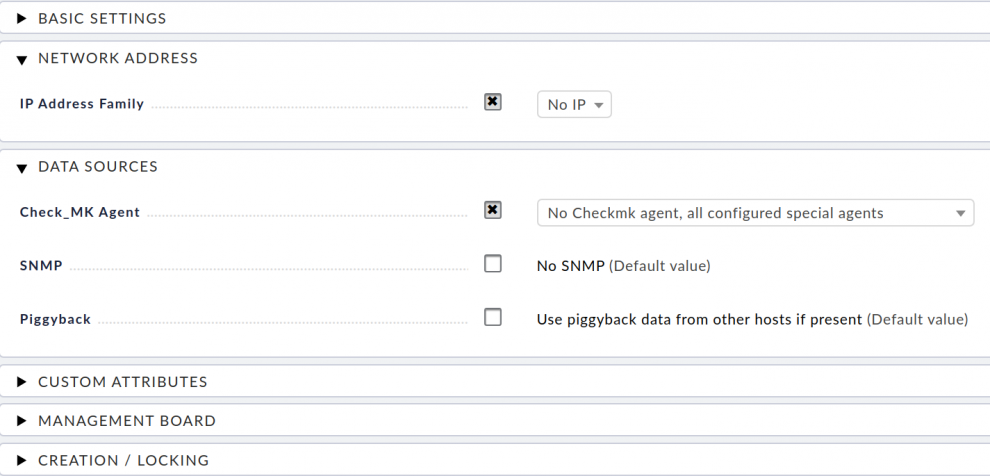
Ein Elasticsearch-Monitoring mit Checkmk aufzusetzen, ist nicht sonderlich kompliziert. Zuerst erstellen wir einen Host, dem Checkmk alle Statusinformationen und Metriken von Elasticsearch zuweisen wird. Dazu klicken Sie auf Create new host und markieren unter Network Address area die Checkbox IP Address Family und wählen im Drop-down-Menü No IP aus. Anschließend klicken Sie im Bereich Data Sources das Feld Check_MK Agent an und wählen die Option No Checkmk agent, all configures special agents aus. Haben Sie den Checkmk Agent installiert, wählen Sie an dieser Stelle die Option Normal Checkmk Agent, all configured special agents aus.
Nun erstellen wir eine neue Regel. In unserem Beispiel handelt es sich um die Regel Check state of Elasticsearch. Gehen Sie zu WATO ➳ Host & Service Parameters und geben Sie Check state of Elasticsearch in das Suchfeld ein. Die gesuchte Regel sollte unter Datasource Programs aufgelistet sein.
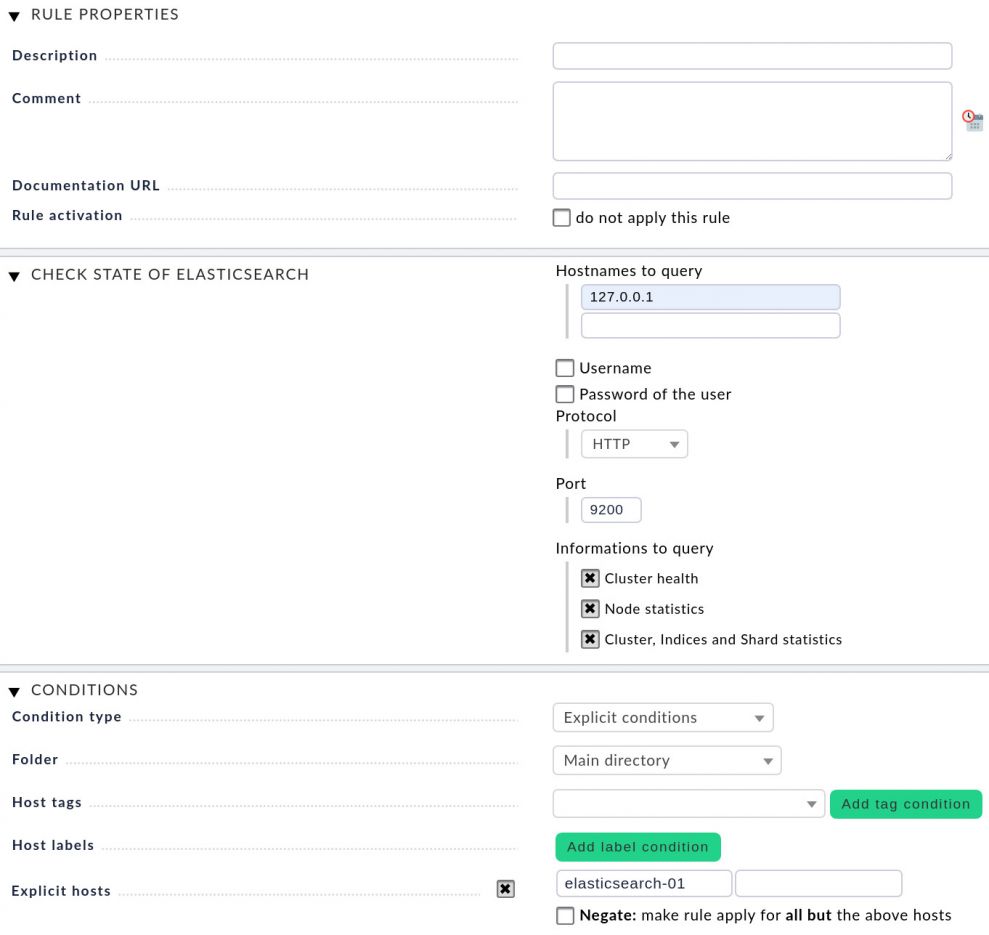
Alle Informationen in der Sektion Rule Properties sind optional. Hier können Sie Beschreibungen und Kommentare hinzufügen. Im nächsten Schritt öffnen Sie den Bereich Check State of Elasticsearch und geben den Host-Namen oder die IP-Adresse der Elasticsearch-Instanz im Textfeld Hostnames to query an. Es ist möglich, mehrere Instanzen anzugeben. Wenn die Verbindung zur ersten Instanz fehlschlägt, wird Checkmk versuchen, die nächste Instanz anzufragen. Checkmk überwacht jedoch nur die erste erreichbare Instanz. Username und Password of the user müssen Sie nur angeben, wenn Sie die Enterprise Edition verwenden. Die Standardversion von Elasticsearch umfasst keine Anmeldeinformationen.
Hinweis: Normalerweise läuft das Elasticsearch nicht auf dem selben Server wie Checkmk wie hier im Screenshot gezeigt.
Spezifizieren Sie nun das Protocol und den Port. In der Standardkonfiguration nutzt Elasticsearch HTTP und lauscht auf dem Port 9200. Im Bereich Informations to query haben Sie die Möglichkeit, die Checkboxen Cluster health, Node statistics, und Cluster, Indices and Shard statistics auszuwählen. Unter Explicit hosts geben sie den Host an, den sie im ersten Schritt erstellt haben. Speichern Sie die gemachten Einstellungen, bevor Sie einen neuen Host anlegen.
Denken Sie daran, dass Checkmk eine noch umfassendere Überwachung bietet, wenn Sie den Checkmk-Agenten auf den Elasticsearch-Nodes installieren und diese anschließend mit Hilfe des Agents überwachen.
Tipp: Mit Checkmk können Sie eigene Dashboards erstellen und so alle Ansichten, Diagramme und andere Elemente auf einer einzigen Seite kombinieren. Mit einem benutzerdefinierten Dashboard ist das Monitoring von Elasticsearch-Clustern ziemlich komfortabel.
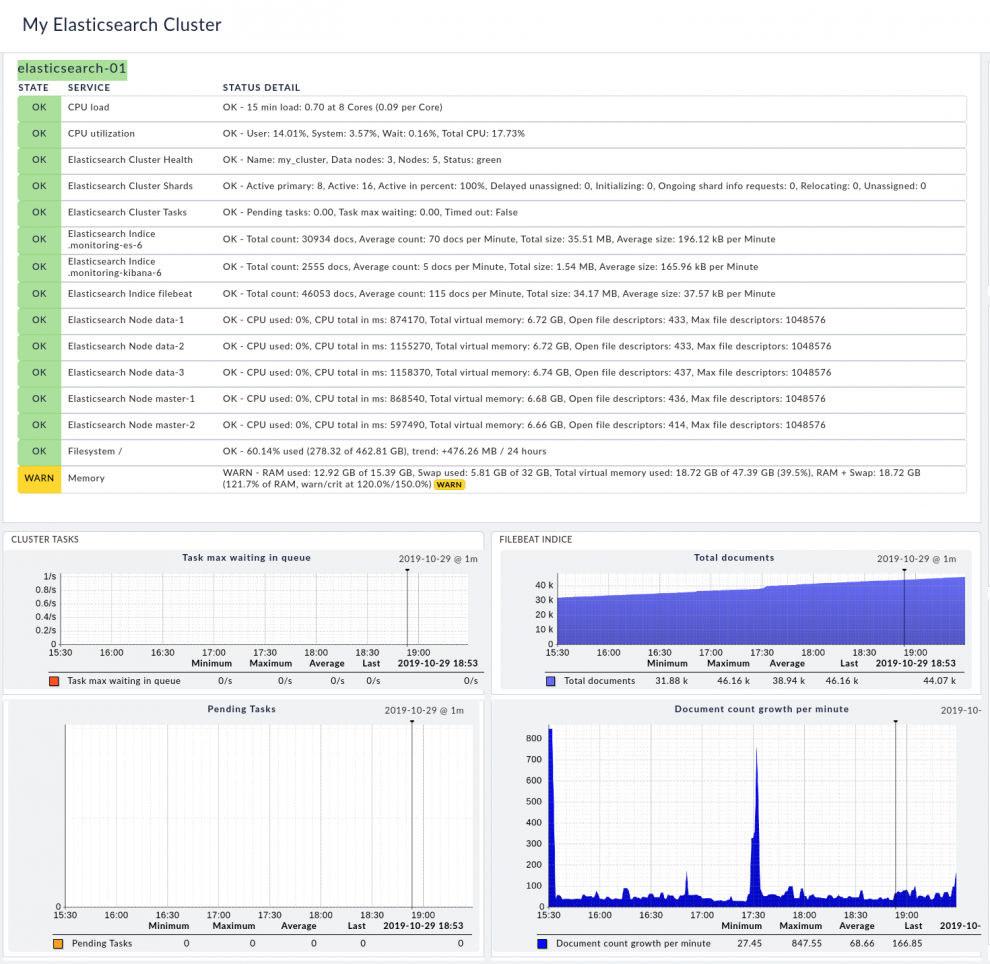
Da Ealsticsearch in Java geschrieben ist, macht es natürlich Sinn, auch die Java Virtual Machine und die Garbage Collection zu überwachen. Dies können Sie mit Checkmk mittels unserer JVM Checkplugins.
Wir hoffen, dass Ihnen unserer Zusammenfassung für das Monitoring von Elasticsearch mit Checkmk geholfen hat. Lassen Sie uns wissen, was Sie darüber denken und wonach Sie suchen!