End-to-End-Monitoring – oder: zu Ende gedacht
 on 16.11.2020
on 16.11.2020
Mit einem Infrastruktur- oder System-Monitoring hat ein IT-Team jederzeit die Gesundheit seiner IT-Infrastruktur im Blick. Auf diese Weise kann es Probleme schnell und einfach identifizieren und ist in der Lage, Störungen zu beheben, noch ehe sie sich auf die IT-Infrastruktur auswirken. Ein Bereich, den ein solches Monitoring jedoch nicht umfasst, ist die Überwachung der Nutzererfahrung: Funktioniert für den Anwender die Software so wie sie sollte oder bremsen lange Ladezeiten die Arbeit des Mitarbeiters aus?
Deutlicher wird dieses Problem durch die wachsende Nutzung von Cloud-Plattformen, -Services und -Infrastrukturen in Unternehmen. Hier hat ein IT-Administrator häufig keinen Zugriff auf die darunterliegende Infrastruktur. Er kann also nicht so tief „unter die Haube“ schauen, wie es bei einer lokalen Infrastruktur möglich wäre. Dadurch gestaltet sich die Ursachenforschung bei einem Problem mit einer Applikation deutlich schwieriger.
Mit einem End-to-End-Monitoring hat der IT-Administrator die Möglichkeit, solche dunklen Bereiche in seiner IT-Umgebung auszuleuchten. Es hat das Ziel, die Nutzung der bereitgestellten IT-Infrastruktur möglichst reibungslos zu gestalten.
Dieser Blog-Artikel soll ein Bewusstsein für die Notwendigkeit von End2End-Tests schaffen und erklären, wie eine Integration solcher Tests in Checkmk gelingt.
TL;DR:
End-to-End-Monitoring stellt sicher, dass Anwendungen aus Nutzersicht korrekt funktionieren – und geht damit über klassische Infrastrukturprüfungen hinaus.
- Es schließt den blinden Fleck zwischen OSI-Schicht 7 und dem Endnutzer, indem die tatsächliche Funktionalität und Performance von Anwendungen aus Anwendersicht getestet wird.
- Robot Framework automatisiert wiederholbare Tests für Web-, Desktop- und individuelle Anwendungen und erleichtert so die Erkennung von Fehlern, Verlangsamungen oder Abstürzen.
- Robotmk integriert diese Tests in Checkmk und ermöglicht deren geplante Ausführung, Ergebniserfassung und Benachrichtigung, sodass Administratoren proaktiv eine stabile User Experience sicherstellen können.
Orientierung im OSI-Modell
Warum End2End-Monitoring wichtig ist, verdeutlicht der Blick auf das OSI-Schichtenmodell. Das Modell zeigt, was ein Administrator mittels eines IT-Infrastruktur-Monitorings überwachen kann - und wo die natürliche Grenze dieser Art von Monitoring ist.

Netzwerkprotokolle bauen in diesem Modell grundsätzlich in Schichten aufeinander auf. Ein Beispiel: Die Echo-Anfrage des ICMP-Checks durchquert die Schichten 3, 2 und 1, ehe sie anschließend durch das Übertragungsmedium (Luft oder Kabel) auf dem Ziel-Host durch Schicht 1, 2 und 3 wieder nach oben wandert. Dort wird sie mit einem Antwortpaket in umgekehrter Laufrichtung bestätigt.
Was im Detail mit dem Paket auf seiner Reise durch diese Schichten passiert, ist für Checkmk irrelevant und soll an dieser Stelle auch nicht das Thema des Artikels sein. Wichtig ist allein, dass auf die Anfrage von Ebene 3 innerhalb einer gewissen Zeit eine entsprechende Antwort eingeht, damit Checkmk den Host als “UP” – also erreichbar – kennzeichnen kann.
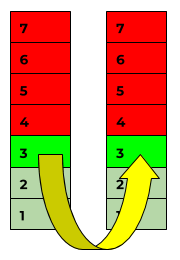
Weil zum Beispiel ein Web-Server mehr können muss, als nur auf ICMP-Anfragen zu antworten, gibt es natürlich auch noch Checks für die Protokolle höherer Schichten.
Wenn Checkmk einen Ziel-Host zum Beispiel mit einem FTP-Check prüft, dann startet das Paket in diesem Fall in Schicht 7 (= dem FTP-Plugin), wandert durch alle Schichten nach unten und beim Ziel-Host wieder ganz nach oben zu Schicht 7, wo der FTP-Server (hoffentlich) arbeitet. Er beantwortet die Anfrage und schickt das Paket anschließend zurück.
Die Farben in der letzten und folgenden Grafik zeigen, was man einerseits exakt wissen und andererseits daraus ableiten kann:
- grün ist die Gewissheit, dass Checkmk und der Zielhost auf Schicht 3 beziehungsweise 7 kommunizieren können. Auf dieser Schicht fallen Metriken an, etwa Paketlaufzeit.
- hellgrün ist die Farbe der Annahme, das heißt, dass Monitoring-System weiß, dass diese Schichten durchlässig sind und die Pakete transportieren. Es weiß aber nicht, ob auf Schicht 2 statt Ethernet beispielsweise das steinalte Token-Ring-Protokoll zum Einsatz kam.
- rot ist das markiert, was nur noch eine Spekulation darstellt: Wenn Schicht 3 funktioniert, ist eine wichtige Voraussetzung dafür gegeben, dass ein FTP-Server darauf laufen kann – es ist aber keinesfalls gesichert.
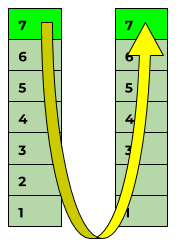
Die Anwendungsschicht
Beim Namen der Schicht 7, der sogenannten"Anwendungsschicht", könnte man jetzt leicht auf die Idee kommen, dass genau dort auch die Anwendungen liegen, mit denen die Anwender arbeiten. Das ist aber nicht der Fall.
Schicht 7 ist lediglich die Ein- und Ausgabeschnittstelle zu den Anwendungen und diese setzen darauf auf. Das wird leider oft durcheinandergebracht.
Angesichts der Tatsache, dass das erweiterte OSI-Modell auf Schicht 8 den Menschen beziehungsweise Anwender definiert, muss man sich eine Zwischenschicht denken, auf der die Software läuft (“Schicht S”).
Und damit wird klar: Mit Monitoring-Checks überprüft man eigentlich immer nur die Voraussetzungen für die Software-Schicht (= alles inklusive. Schicht 7) – aber nie ihren Zustand selbst!
Die End-User-Experience
Was ist eigentlich die Aufgabe eines Administrators?
- Festplatten tauschen?
- Latenzen beobachten?
- Updates einspielen?
Ja – und doch Nein. Es gibt eigentlich genau einen einzigen Job: Er muss sicherstellen, dass die Anwender beim Gebrauch der bereitgestellten Dienste und Applikationen zufrieden sind, also eine gute "Enduser-Experience" haben.
Das ist, woran die IT gemessen und beurteilt wird. Alle anderen Aufgaben eines Administrators sind nur eine Folge dieser "Mission":

Dass die eingesetzte Software funktioniert, bleibt also nur eine Spekulation, solange der Administrator sie nicht direkt, sondern nur bis Schicht 7 überwacht.
Unentdeckt bleiben in einem solchen Fall möglicherweise weiterhin:
- Dienstgüte/Performance extern gehosteter Anwendungen,
- allmähliche Verschlechterungen von Start- und Ladezeiten,
- vermeintlich zufällige Programmabstürze,
- Anzeigefehler,
- Probleme in Prozessketten,
- veraltete Daten usw.
Mit diesem Vorwissen lässt sich nun auch erklären, welche Bedeutung hinter dem Begriff "End-to-End" steckt: Es geht darum, beim Monitoring im OSI-Modell noch weiter nach oben zu rücken – bis an die Grenze von Computer zu Mensch. An das Ende eben. Diese Schicht testet man beim End-to-End-Monitoring aus der Perspektive des Anwenders.
Robot Framework
Nun ja – man lässt testen. Robot Framework gilt als eines der besten Open-Source-Tools für automatisiertes Testen. Es hangelt sich wie ein Roboter immer wieder durch die gleichen Pfade in einer Applikation und kann dabei mit jeder Art von Applikation umgehen, sei es Web-basiert oder installiert auf Windows oder Linux.
Robot Framework wird übrigens nicht nur zum Testen von Software eingesetzt. Es ist auch hervorragend für RPA (Robotic Process Automation) geeignet. Dahinter steckt die Idee, Arbeitsabläufe zu automatisieren, die normalerweise nur Menschen ausführen können, etwa stupides Eingeben von Daten in Bestands-Software, die keine Import-Schnittstelle hat. Robot Framework kommt damit dem Bild eines "Software-Roboters am Fließband" schon recht nahe!
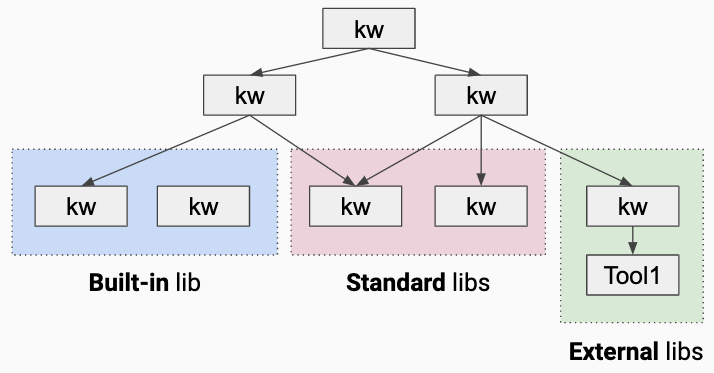
Wenn es ein Feature gibt, das Robot Framework von allen anderen Test-Tools abhebt, dann ist das sicherlich der "Keyword-Driven"-Ansatz. Robot wird mit Libraries erweitert, die beispielsweise die Testmethoden für Selenium, AutoIT, SAP, Sikuli etc. über spezielle Keywords bereitstellen. Keywords abstrahieren den Python-Programmcode, der zum Beispiel für Selenium-Tests notwendig wäre.
Keywords lassen sich wie Funktionen in einer Skriptsprache ineinander schachteln und mit Ein- und Ausgabeparametern versehen. Sicher bietet die Programmierung von Tests in Python die maximale Freiheit, grenzt den Kreis derer, die Tests schreiben, allerdings auf Programmierer ein. Weil Robot-Keywords Python-Code kapseln und abstrahieren, erleichtern sie das Schreiben und Lesen/Verstehen von Tests erheblich.
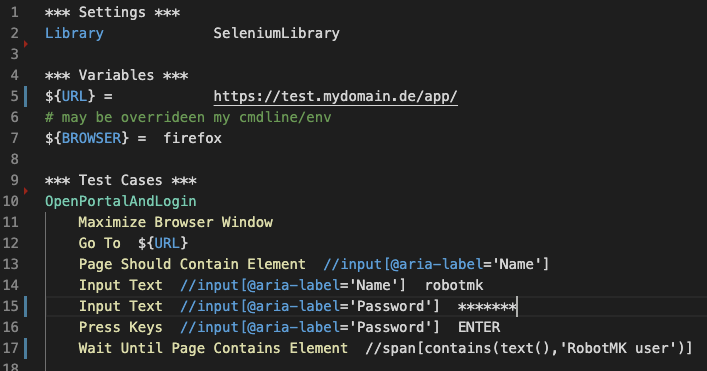
In diesem Ausschnitt eines Robot-Files wird die Selenium-Library für Web-Tests verwendet (Zeile 2). Nach der Definition zweier Variablen im Abschnitt “Variables” beginnt die “Test Cases”-Sektion. Der Testcase “OpenPortalAndLogin” führt eine Reihe von Keywords der Selenium-Library aus, um den Login auf einer Web-Applikation auszuführen.
Bei der Formulierung von Tests sollte man stets darauf achten, den jeweils gewünschten SOLL-Zustand zu verifizieren, wie Zeile 17 zeigt: der Login war nur dann erfolgreich, wenn ein span-Element existiert, das den Text “Robotmk user” enthält.
Die Integration solcher Robot-Tests in das Monitoring war bislang nicht möglich, geht es hierbei doch sowohl um die regelmäßige Ausführung als auch um die Auswertung der Ergebnisse – denn schließlich sollen funktionale oder leistungstechnische Fehler auch alarmiert werden.
Robotmk
"Robotmk" ist eine Erweiterung speziell für Checkmk und schließt diese Lücke.

Es ist im Checkmk Exchange als MKP (MK-Package) erhältlich. Robotmk v1 ist kompatibel mit allen Checkmk 1.6 Versionen sowie mit Checkmk 2.0 aufwärts. Seit Checkmk 2.3 ist Robotmk als neues Add-on namens Checkmk Synthetic Monitoring integriert. An dieser Stelle sprechen wir jedoch über Robotmk v1.
Das Plugin wird entweder asynchron über den Checkmk-Agenten oder extern per Taskplaner getriggert und führt die Robot-Testcases auf der Zielmaschine aus.
Das Ergebnis eines jeden Tests wird über den Agenten-Output zum Checkmk-Server transportiert. Dort wertet der Check nicht nur Laufzeiten verschiedener Testabschnitte aus, sondern beeinflusst auch die Länge und Gestalt des Outputs. Welche Testabschnitte Performance-Daten generieren sollen, legt eine weitere Regel fest.
Mittels der Discovery-Regel ist es auch möglich, aus einzelnen Abschnitten eines Tests separate Services zu erzeugen. Das ist zum Beispiel besonders dann hilfreich, wenn Robot einen Test mehrfach mit unterschiedlichen Testdaten ausführt oder für die Testabschnitte unterschiedliche Teams alarmiert werden müssen. Auch eine Art “Echtzeit-Fortschrittsanzeige” ist damit in Nagvis für Test-Suites realisierbar.
Mit dem OSI-Schichtenmodell vor Augen wird klar, warum die "Schicht S" über der Applikationsschicht kein blinder Fleck im Monitoring bleiben sollte – ist sie doch die Schicht, mit der der Anwender mit der Infrastruktur interagiert.
Mit End-to-End-Monitoring auf Basis von Robot Framework lassen sich Funktionalität und Performance von Applikationen in dieser Schicht überwachen. Es stellt somit eine ideale Ergänzung zu Checkmk dar, weil es überwacht, was der Anwender sieht.
Weitere Vorteile sind:
- Überwachung des reibungslosen Ineinandergreifens von Technologien und Funktionsketten.
- Standortübergreifende Tests und Auswertungen (zum Beispiel SLA-Reports) schaffen klare Diskussions- und Entscheidungsgrundlagen.
- Frühwarnsystem für den Applikationsbetrieb. Proaktives Beseitigen aufkommender Probleme erhöht die Verfügbarkeit und sichert das Image und Vertrauen in die IT.
- Kurzum, End-to-End-Monitoring ist die konsequent weitergedachte Überwachung der letzten und wichtigsten Ebene zwischen Mensch und Maschine.
In unserem nächsten Blog-Artikel zeigen wir Ihnen, wie Sie einen Robot-Framework-Test einrichten und in Checkmk integrieren, indem Sie den Robotmk Scheduler in Checkmk 2.3 verwenden.
Über den Autor:
Monitoring war schon immer eine Konstante in Simons 20-jähriger IT-Karriere – zunächst als Administrator, dann als Berater und seit 2018 in seiner eigenen Firma ELABIT GmbH, die er gegründet hat, um sich auf das automatisierte Testen von Anwendungen und die Integration solcher Tests in Checkmk zu konzentrieren. Die Lösung "Robotmk" ist das Ergebnis seiner Bemühungen und wird in der Checkmk-Community sehr geschätzt.
Wenn er nicht gerade als Produktmanager bei Checkmk arbeitet und die Weiterentwicklung von Robotmk koordiniert, hilft er Kunden auf der ganzen Welt, synthetisches Monitoring in ihre Umgebung zu integrieren.