Netzwerk-Monitoring: Four Rules to rule them all
 on 09.06.2020
on 09.06.2020
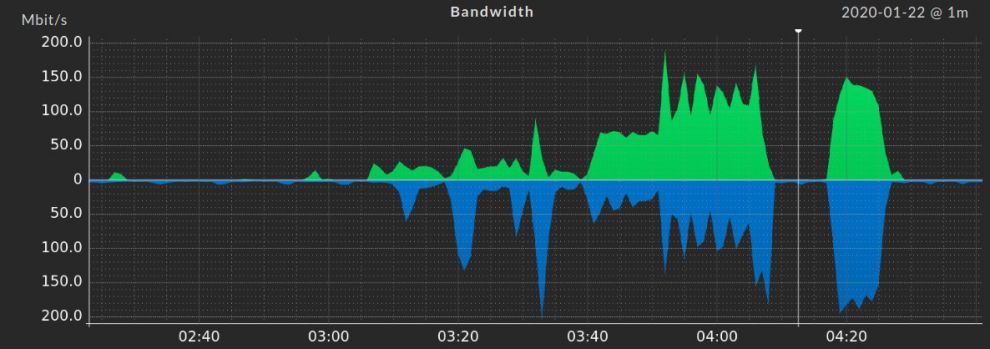
Netzwerk-Monitoring kann eine anspruchsvolle Aufgabe sein. Mit den richtigen Tools lässt sich jedoch problemlos ein holistisches Monitoring aufsetzen und Probleme im Netzwerk aufspüren, die man vorher möglicherweise noch gar nicht bemerkt hat.
Wenn Sie diesen Blogpost gelesen haben, werden Sie in der Lage sein, sich auf das Beheben von aktuellen Problemen zu konzentrieren oder Kaffee zu trinken, anstatt Ihr Monitoring zu konfigurieren. Ich werde hier mein Vorgehen beim Netzwerk-Monitoring mit meiner Erfahrung aus über 20 Jahren als Netzwerkspezialist mit Ihnen teilen. Mein Ziel ist es, dass Sie weniger Zeit für externe Consultants ausgeben müssen, die versuchen die falschen Dinge zu beheben. Stattdessen sollen Sie die wahren Flaschenhälse und Performance-Probleme in Ihrer Netzwerkumgebung identifizieren können.
Bitte beachten Sie: Dieser Blogpost basiert auf Checkmk 1.6. Wenn Sie bereits Checkmk 2.0 nutzen, und ein holistisches Netzwerk-Monitoring aufsetzen wollen, finden Sie in unserem Artikel 'Netzwerk-Monitoring mit Checkmk: 3 rules to rule them all' alle Informationen.
Es ist eine Herausforderung, alle Interfaces Ihrer Switches im Auge zu behalten, ohne dabei in einer Flut aus falschen Alarmen zu versinken. Es gibt jedoch ein paar Tricks, wie man seine automatische Netzwerkerkennung und -alarmierung einstellen kann, um eine kompakte Übersicht zu erhalten – ohne zu viel Zeit für das Aufsetzen des Netzwerk-Monitorings zu benötigen.
Performance-Probleme basieren häufig auf Netzwerkfehlern und im schlimmsten Fall setzen Unternehmen kein Monitoring ein, das dabei helfen kann, diese Probleme zu lindern. Solche Unternehmen beauftragen dann häufig Administratoren und Consultants, die Stunden damit verbringen, ein Problem an der falschen Stelle zu beheben. Ein nicht-performantes Netzwerk kann einem Unternehmen ernsthafte Verluste bescheren.
Unabhängig davon, ob es sich um eine große oder kleine Netzwerkumgebung handelt, ist es immer eine gute Idee, alle Netzwerk-Interfaces zu überwachen. Nur auf diese Weise lassen sich Probleme wie gebrochene Patch- oder Installationskabel, verschmutzte Fiber Optics, defekte Firmware und Konfigurationsfehler wie Duplex-Fehlpaarungen entdecken. Eventuell denken Sie, dass das in ihrem Netzwerk nicht der Fall ist – aber vielleicht haben Sie diese Probleme bis jetzt nur noch nicht entdeckt?
Die Umsetzung kann sich in der Realität etwas schwierig gestalten, da es viele Ports in einem Netzwerk gibt und Systemadministratoren bereits jetzt schon viele Aufgaben bewältigen müssen. Ein reiner Port-Scan wird normalerweise nicht ausreichen, da beispielsweise Access Ports, also Ports mit einem Endnutzer, offline gehen, wenn der Anwender seinen angebundenen Computer ausschaltet. Standardmäßig führt dies dann zu einem falschen Alarm in den meisten Monitoring-Lösungen, weil es absolut in Ordnung ist, wenn ein Nutzer seinen PC herunterfährt. Auf der anderen Seite ist es keine Option, sich jeden einzelnen Port anzuschauen und ihn individuell zu verwalten.
Der Blog soll daher eine einfache Methode aufzeigen, wie Sie mit Checkmk Ihr Netzwerk-Monitoring auf den richtigen Weg bringen. Es benötigt eine gewisse Vorbereitung, genauer gesagt die Benennung der wichtigsten Switch-Ports, und das Aufsetzen von lediglich vier Regeln in Checkmk. Alle Schritte werden in diesem Artikel detailliert erklärt. Dies ist jedoch nur ein Lösungsweg. Es gibt natürlich auch andere Möglichkeiten. Für den Fall, dass Sie nicht weiterkommen oder denken, dass es noch alternative Methoden gibt, hoffen wir, dass Sie ihre Erfahrung im Kommentarbereich unter diesem Post oder in unserem Forum teilen.
Wenn Sie alle Schritte richtig umgesetzt haben, sollten Sie eine komplette Übersicht über ihr Netzwerk erhalten und nur Alarme bekommen, die auch eine Reaktion erfordern.
Netzwerk-Monitoring konfigurieren: Wichtige Ports benennen
Bevor wir anfangen, in Checkmk mit Regeln zu arbeiten, die die Erkennung und das Monitoring verbessern, ist es nötig, dass Sie ein Namenskonzept für ihre Netzwerk-Interfaces einführen. Ziel des Konzepts ist es, zwischen Access und Non-Access Ports unterscheiden zu können.
Das ist nicht nur für Nutzer nützlich, die sich die Ports im Dashboard anschauen, weil sie dann ein besseres Gespür für die Daten bekommen. Es ist außerdem für eine automatisierte Differenzierung zwischen Ports in Ihrem Monitoring nötig, damit man auf diese Weise Alarme basierend auf ihrem Port-Typ behandeln kann.
Standardmäßig haben Ports keine Namen. Stattdessen sehen Sie normalerweise eine Liste von Interfaces, die Nummern und technische Beschreibungen enthalten, ähnlich wie dieses Beispiel hier:

Das allein ist jedoch nicht ausreichend, um ein granulares Regelwerk für die Monitoring-Konfiguration aufzusetzen. Gleichzeitig ist das der Grund, warum es schwierig ist, wichtige Ports auf irgendeine Art mit Hilfe der Auto-Discovery in Checkmk zu finden. Um also mit einem angemessenen Monitoring beginnen zu können, ist es nötig, das Netzwerk entsprechend vorzubereiten.
Der erste Schritt ist es, die wichtigsten Schnittstellen innerhalb des Netzwerkgeräts mit einem Namen zu versehen. Die Benennung sollte für Menschen lesbar sein, etwa „Uplink core3“, „esx1-vmnic3“ oder „Uplink MPLS 10 Mbit“. Sie können die Ports auch nach ihren Zweck oder ihren Ort benennen, etwa „Uplink Berlin“. Egal wie Sie sich entscheiden, die Namensgebung sollte dabei so konsistent wie möglich bleiben. Es ist außerdem wichtig, das ein Name nicht nur Nummern enthält – Buchstaben und Zahlen sind jedoch in Ordnung – da ansonsten die erstellten Regeln nicht funktionieren werden. Warum das so ist, erkläre ich an späterer Stelle ausführlich.
Beachten Sie, dass Sie die Ports auch für die später genutzten Regeln richtig benamsen:
- Jeder mit Namen versehende Port wird als wichtig erachtet. Status- oder Geschwindigkeitsänderungen werden überwacht. Error-Schwellenwerte festgelegt.
- Jeder Port der keinen Namen aufweist wird als Access Port behandelt. Wir werden nur Errors für diese Ports monitoren und Status- oder Geschwindigkeitsänderungen ignorieren, damit er offline gehen kann, ohne dadurch einen Alarm auszulösen.
Sie können die Namen für die Ports in jedem Switch direkt setzen. Bei Cisco lässt sich das beispielsweise über den Description-Befehl im Interface-Kontext umsetzen. Für HPE/Aruba-Switches ist es mit dem name-Befehl möglich.
Auch wenn die Benamsung aufwändig ist, lohnt sie sich auf jeden Fall, da Sie dadurch gleichzeitig Ihre wichtigste Ports auf diese Weise dokumentieren. So wissen Sie sofort, welches Gerät bei einem Zwischenfall betroffen ist. Sie erhalten dadurch also eine Netzwerk-Dokumentation auf die ein Live-Monitoring aufgesetzt ist.
Wenn sie Ihre Ports benannt haben, ist es an der Zeit, das Monitoring zu konfigurieren. Die bisher genannten Schritte sind prinzipiell für jedes Netzwerk-Monitoring hilfreich – von jetzt an fokussieren wir uns aber darauf, wie sich mit Checkmk ganz unkompliziert ein komplettes Netzwerk-Monitoring aufsetzen lässt.
Implementierung des Monitorings: Eine Regel, um sie alle zu beherrschen
Wenn Sie versuchen, ein Netzwerk-Monitoring allein mit der Auto-Discovery-Funktion in Checkmk aufzusetzen, erhalten Sie eine Liste aller Ethernet-Schnittstellen, die aktuell online sind. Anschließend überwacht Checkmk den Status, die Geschwindigkeit und die Fehlerrate dieser– und wirklich nur dieser – Ports und versendet einen Alarm, wenn sich einer dieser Werte verändert. Wie bereits erwähnt, bleiben nicht alle Ports für immer online und verursachen dann Alarme, wenn sie offline gehen. Dabei handelt es sich um potenzielle False Positives, die dazu führen, dass die Administratoren anfangen Monitoring-Alarme zu ignorieren.
Die folgenden fünf Schritte sind eine Anleitung für das Aufsetzen eines holistischen Netzwerk-Monitorings mit Checkmk mit lediglich vier Regeln. Nach der Umsetzung erhalten Sie eine Übersicht über Ihr Netzwerk und bekommen nur Alarmierungen, wenn wirklich etwas falsch läuft.
Schritt1: Differenzieren Sie zwischen Description und Alias durch das Erstellen eines Tags
Unglücklicherweise erlaubt SNMP zwei Tabellen für Interface-Namen: Description und Alias. Welche Tabelle genutzt wird, hängt vom Hersteller oder sogar vom Gerät ab. Im Vorbereitungsteil haben wir bereits die wichtigsten Schnittstellen durch die Nutzung der Description oder des Name-Befehls mit einem Namen versehen. Andere Hersteller bieten hierfür möglicherweise andere Befehle oder lediglich eine GUI an. Jetzt müssen wir nur noch einen Weg finden, um Checkmk zu sagen, welche Tabelle es für einen Host benutzen soll. Ich verwende einen Host tag als einen virtuellen Lichtschalter um entweder die Alias- oder die Description-Tabelle zu nutzen. Das Anwenden eines Host tags erlaubt uns nicht nur, einzelne Hosts zu taggen, sondern ganze Ordner. Dies vereinfacht die Erweiterung und Einstellung.
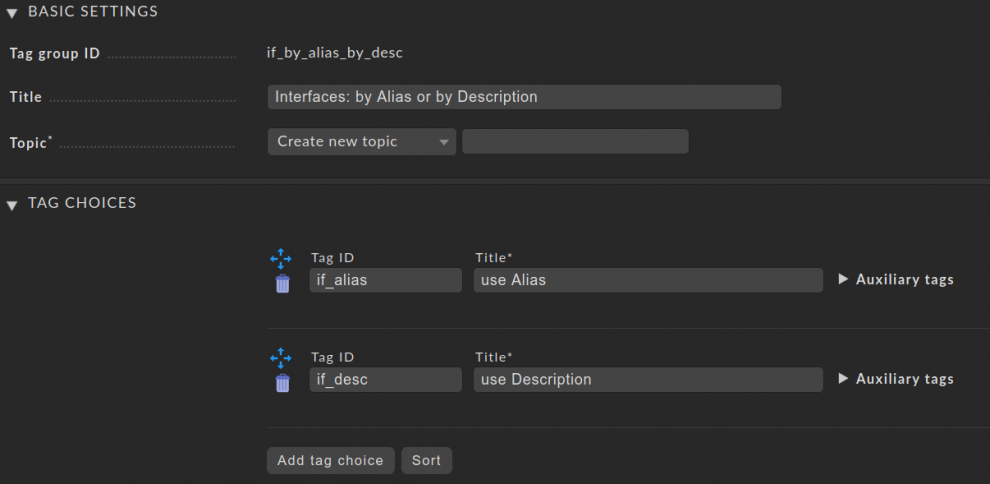
- Öffnen Sie das WATO-Modul Tags und erstellen Sie eine New tag group. Diese Gruppe wird uns später bei Schritt 5 helfen, wenn es darum geht, zwischen der Alias- und Description-Tabelle auf ihren Netzwerkgeräten zu wechseln.
- In den Basic Settings klicken Sie zweimal auf Add tag choice, um die beiden benötigten Felder hinzuzufügen. In die erste Tag ID schreiben wir „if_alias“ und in den Titel „use Alias“. Im zweiten Feld geben wir „if_desc“ als Tag ID ein und nutzen „use Description“ als Titel. Dadurch sind wir in der Lage, unsere Switches – oder noch besser die Ordner – je nach Bedarf zu taggen. Der Screenshot unten zeigt, wie es aussehen sollte.
- Anschließend speichern Sie den Tag und wenden die Änderungen in Checkmk an. Jetzt sollten Sie den neuen Tag sehen, wenn Sie in der WATO unter Tag groups auf Tags
Definiert man „if_alias“ als ersten Eintrag unter Tag Choices, verwendet Checkmk standardmäßig die Alias als Tag. Das ist ideal, da die meisten Hardwarehersteller die Alias-Tabelle verwenden.
Schritt 2: Entdecken und monitoren Sie alle Interfaces und Ports
Jetzt ist es an der Zeit, zwei weitere Regeln aufzusetzen, die sich nur punktuell unterscheiden. Ich starte mit dem Anlegen einer Regel für den Umgang mit jenen Interfaces, die die Alias-Tabelle als Quelle für ihre Interface-Namen benutzen.
- Geben Sie unter WATO ➳ Host & Service Parameters in die Suchzeile Network Interface and Switch Port Discovery ein, um die benötigte Regel zu finden. Sie sollten diese unter Discovery – Automatic Service Detection finden. Klicken Sie auf Network Interface and Switch Port Discovery.
- Anschließend klicken Sie auf Create rule in Folder: Main directory. Anschließend können Sie die benötigte Regel konfigurieren.
- Nutzen Sie bei Bedarf das Comment Field für die Dokumentation. Sie können auch die URL für diesen Artikel in das Feld für die Dokumentations-URL einfügen.
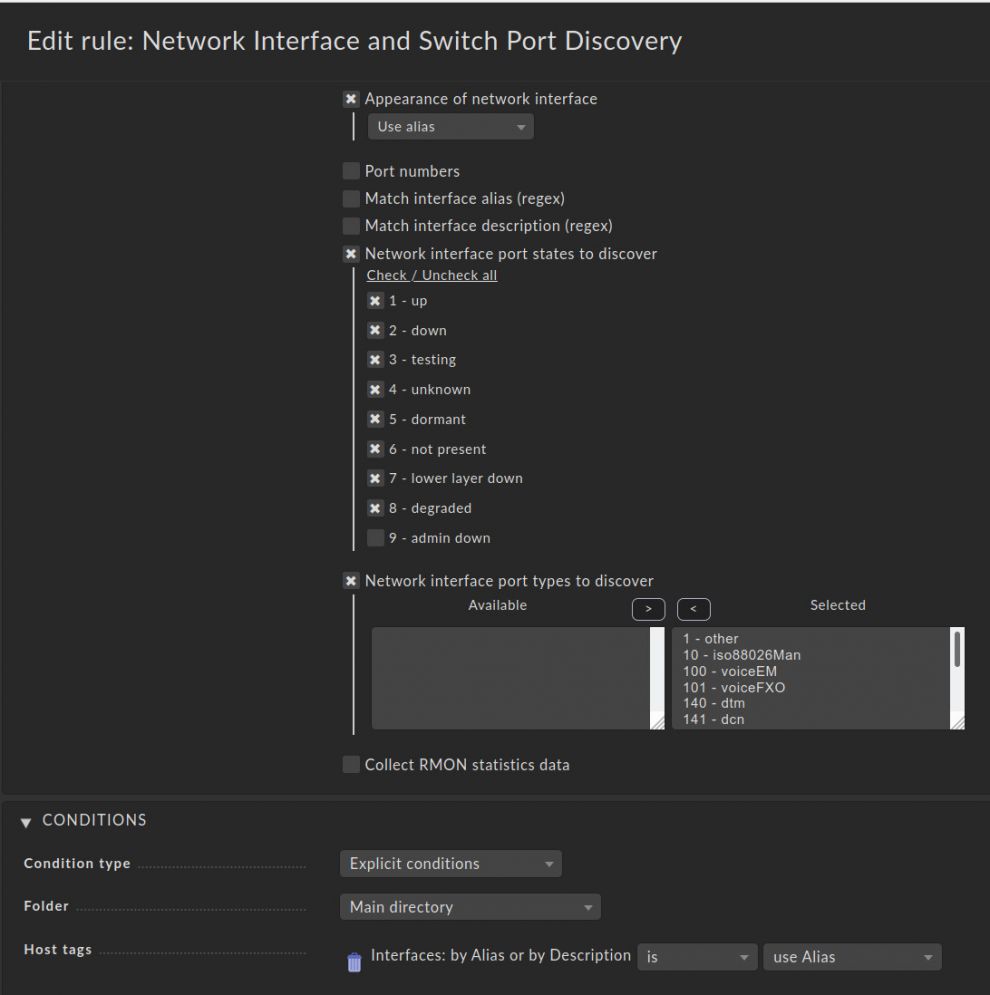
- Aktivieren Sie Appearance of network interface und wählen Sie Use alias.
- Markieren Sie die Checkbox Network interface port states to discover und aktivieren Sie alle möglichen Optionen mit Außnahme von 9 – admin down. Dadurch sind alle Port-Status eingeschlossen. Warum nicht die Option Nummer 9? Das hätte einige Auswirkungen, die weit über diesen Artikel hinausgehen. Glücklicherweise brauchen wir sie nicht für das Konzept, das wir in diesem Artikel vorstellen.
- Um Ihr Monitoring zu komplettieren, müssen Sie nur noch Network interface port typest to discover aktivieren und diese verfügbar machen, indem Sie alle Auswahlmöglichkeiten von rechts (Selected) nach links (Available) bewegen.
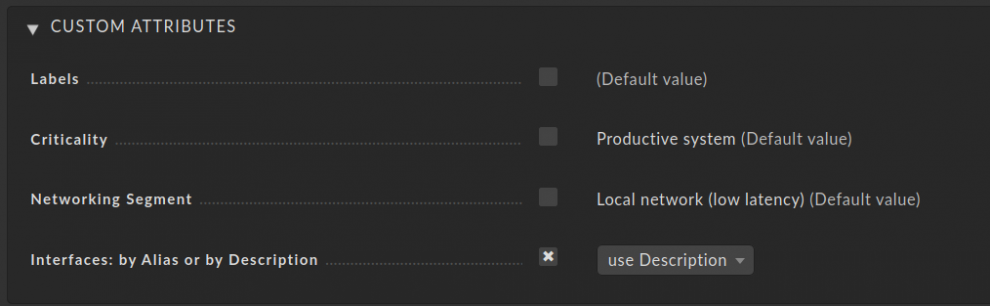
- In der Conditions-Sektion wählen Sie nun unter Host tags ➳ Interfaces: by Alias or by Description ➳ is und use Alias.
- Speichern Sie die Regel.
Die Regel sollte jetzt so aussehen wie im Screenshot:
Durch diese Regel überwachen Sie nun alle Ports in Ihrem Netzwerk, auch wenn diese offline sind. Diese Regel findet jedoch nur auf Geräten Anwendung, auf denen das Host tag use Alias angewendet wird – was ja unser Standardfall ist. Als nächstes benötigen wir nun eine Regel für unsere Netzwerkgeräte, die ihren Interface-Namen aus der Description-Tabelle beziehen. Dafür reicht es aus, die eben geschaffene Regel zu klonen und minimal anzupassen.
- Nachdem Sie die Regel im Schritt davor gespeichert haben, landen Sie in der Rule Overview. Hier können Sie diese Regel nun klonen, indem Sie den clone-Knopf

- In der geklonten Regel müssen Sie lediglich unter Conditions ➳ Host tags use Alias durch use Description ersetzen sowie die Einstellung Appearance of network interface auf Use Description ändern. Der Rest bleibt unverändert.
- Regel abspeichern.
Damit haben Sie ein komplettes Monitoring ihrer Ports eingerichtet. Jetzt widmen wir uns der Handhabung der Access Ports.
Schritt 3: Monitoring Ihrer Access Ports
Ich lege Ihnen wärmstens ans Herz, dass Sie auch Ihre Access Ports ins Monitoring aufnehmen. Dabei sollten Sie Status- und Geschwindigkeits-Änderungen ignorieren und stattdessen nur Fehlerraten überwachen. Auf diese Weise erhalten Sie keine Notification von ihrer Monitoring-Instanz, wenn ein Nutzer seinen Computer ausschaltet. Sie bleiben aber informiert, wenn ein Fehler auf einem Port auftritt. Das kann ein Indikator dafür sein, dass beispielsweise ein Kabel gebrochen ist oder ein anderes Problem auftritt, das Sie sich anschauen sollten.
Um das umzusetzen, erstellen wir nun eine dritte Regel für unser Netzwerk-Monitoring. Wie zuvor machen wir das in der WATO über Host & Service Parameters. Dieses Mal suchen wir die Regel Network interfaces and switch ports. Diese befindet sich im unteren Ende unter Networking. Anschließend klicken Sie darauf und erstellen eine Regel im Main directory mit folgender Konfiguration:
- Nutzen Sie bei Bedarf das Comment field für die Dokumentation.
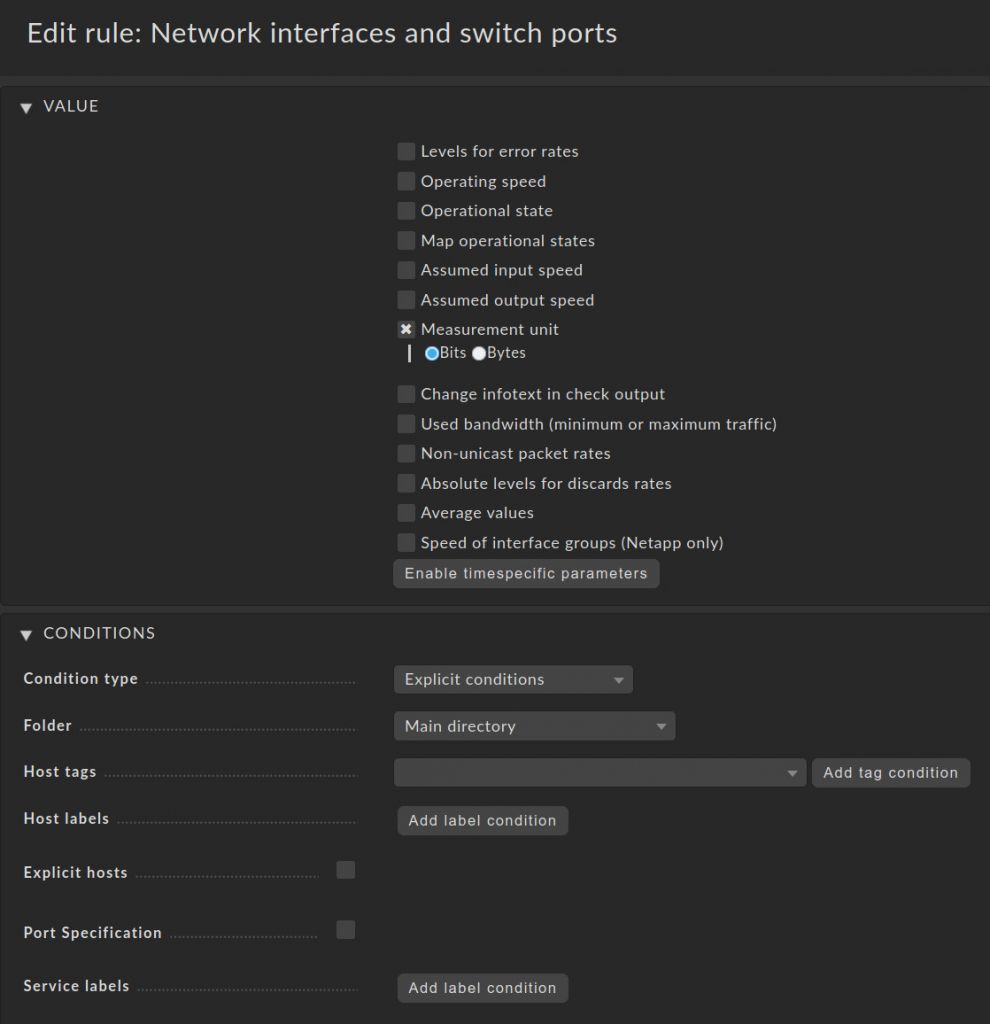
- Unter Values, markieren Sie Operating speed und wählen ignore speed im Menü aus.
- Direkt darunter wählen Sie Operational state aus und setzen die Option auf Ignore the operational state.
- Unter Conditions setzen sie die Port Specification auf \d+
- Speichern Sie die Regel.
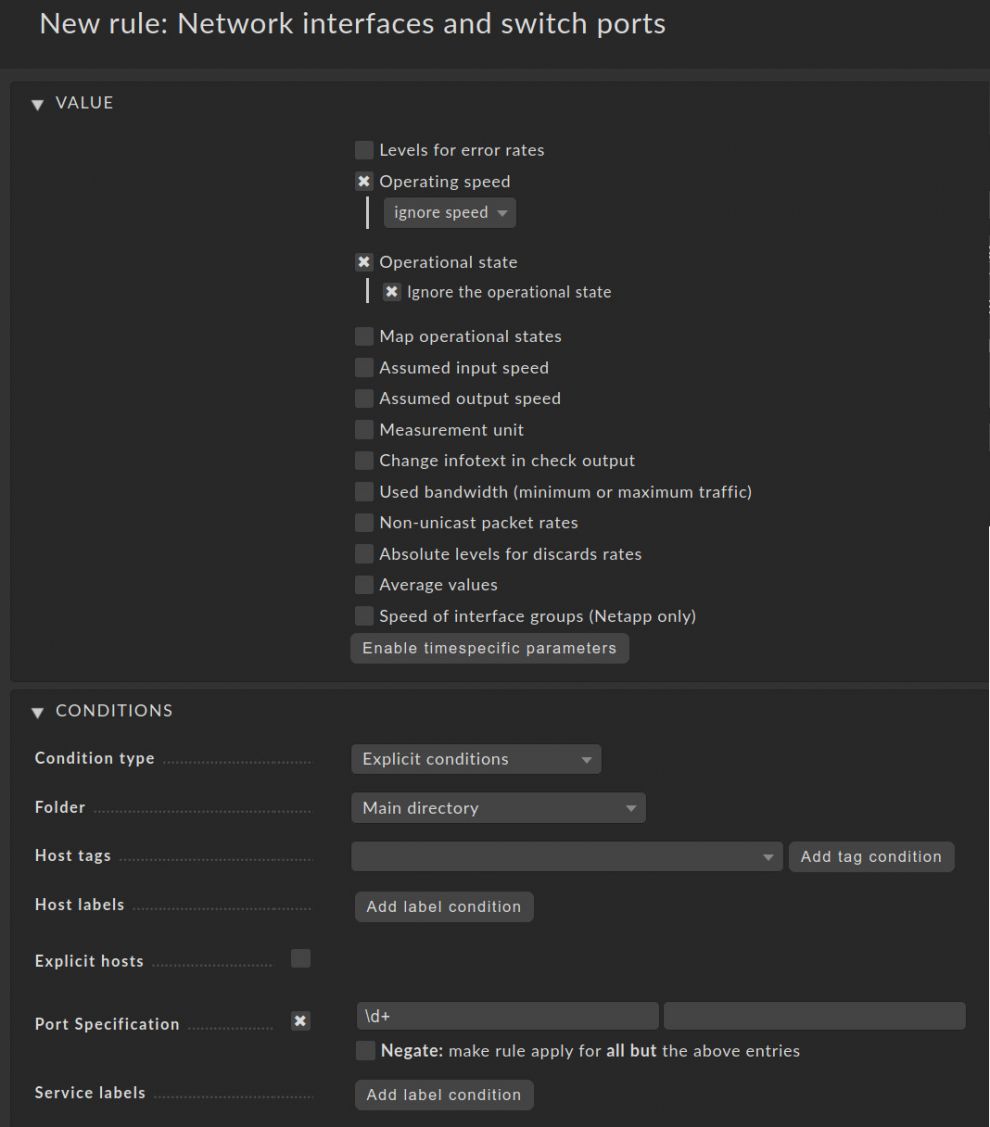
Und hier beginnt der Zauber! In der Condition verwenden wir eine einfache Regular Expressions, um die Access Ports zu identifizieren. \d+ trifft auf alle Schnittstellen zu, die nur Nummern und keine Buchstaben beinhalten. Das heißt, dass nur Ihre Access Ports, die keinen Namen haben, von der Kondition betroffen sind, da sie typischerweise nur Nummern beinhalten. Das ist auch der Grund, warum es wichtig ist, ein konsistentes Schema bei der Benamung zu verwenden, da dies ein einfacher Weg ist, Access Ports zu identifizieren und zu behandeln.
Der Trick funktioniert in den meisten Fällen. Jedoch nutzen einige Hersteller ein technisches Namenschema anstelle einer Index-Nummer. In solchen Fällen können Sie je nach Bedarf weitere geeignete Regular Expressions im Feld Port Specification hinzufügen. Wenn zum Beispiel ein Hersteller seine Interfaces „GigabitEthernet 1/0/1“ benennt, lässt sich der reguläre Ausdruck GigabitEthernet auf alle Interfaces passen, die mit „GigabitEthernet“ beginnen.
Schritt 4: Die richtigen Daten für den Netzwerk-Traffic verwenden
Normalerweise wird der Netzwerk-Traffic in Bits pro Sekunde gemessen. Aber vor einiger Zeit haben Checkmk-Entwickler entschieden, dass Bytes pro Sekunde der standardmäßige Weg sein sollte. Wir überlegen, das früher oder später wieder zu ändern.
Wir müssen diesen Aspekt jedoch mit unserer vierten Regel berücksichtigen.
- Fügen Sie dafür eine weitere Regel unter Network interfaces and switch ports hinzu
- Sie können alle Felder leer lassen und nur die Measurement unit auf Bits ändern. Setzen Sie keine Condition. Auf diese Weise erstellen Sie eine globale Regel für das Monitoring. Global meint, dass diese im Main directory angewendet wird und immer die letzte Regel sein wird, die Checkmk verwendet.
- Speichern Sie diese vierte und letzte Regel.
Schritt 5: Konfigurieren Sie ihre Folders oder Hosts so, dass sie Alias oder Description verwenden
Im letzten Schritt nutzen wir den Tag aus Schritt 1, um unsere Hosts – oder noch effektiver: unsere Folder – zu konfigurieren, damit sie Checkmk sagen, welche Hosts Alias oder Description für die Benennung ihrer Netzwerk-Schnittstellen verwenden.
Wir haben use Alias als ersten Wert in der Tag group gesetzt, sodass dies unser Standard ist. Schauen Sie sich in Ihrer Monitoring-Umgebung einige Hosts an, um zu sehen, ob Sie die erwarteten Informationen erhalten. Eventuell müssen Sie dafür zunächst eine Service Discovery durchführen. Ist es der Fall, dass Sie nur Interface-Nummern erhalten, sollten Sie diesen Host oder Folder anweisen use Description zu nutzen, indem Sie den Tag aus Schritt 1 verwenden.
Sie können Ihre Hosts in Checkmk auch in Foldern gruppieren. Dadurch erbt ein Host alle Attribute von seinem Ordner. Auf diese Weise wird das Host tag an alle darin befindlichen Hosts weitergegeben und Sie verschwenden keine Zeit, weil Sie nicht jeden Host einzeln behandeln müssen. Normalerweise ist es sinnvoll, eine Ordnerstruktur auf Basis eines Gerätetyps zu wählen.
Nachdem Sie die Geräte mit dem passenden Tag versehen haben, führen Sie (erneut) eine Auto-Discovery Ihrer Hosts durch. Im Idealfall erhalten Sie nun eine lange Liste mit Interfaces.
Bitte berücksichtigen Sie, dass der Status OK eines unbenannten Access Ports nicht länger heißt, dass dieser Port online ist, da wir lediglich Fehlerraten dieser Ports ins Monitoring aufgenommen haben.
Netzwerk-Monitoring innerhalb weniger Minuten einrichten
Der Blog hat gezeigt, wie Sie ihr Netzwerk inklusiver aller Ports monitoren können. Das Ergebnis sollte eine effiziente und komplette Übersicht Ihres Netzwerks und aller Interfaces sein. Darüber hinaus sollten Sie nur noch wichtige Alarme erhalten. Das alles basiert auf einer Benamsung der wichtigen Ports im Netzwerk und vier erstellten Rules innerhalb von Checkmk.
Auf den Weg dahin kann es natürlich noch ein paar Herausforderungen geben – schließlich ist jede IT-Umgebung anders. Diese vier Regeln haben mir jedoch dabei geholfen, viele Probleme in Netzwerken zu finden, die zuvor nicht bekannt waren. Es wäre ein vorzeitiges Weihnachtsgeschenk für mich, Alias und Description nicht getrennt behandeln zu müssen – aber jeder der mit SNMP arbeitet weiß, dass es ein notwendiges Übel ist.
Die Vorbereitungen scheinen dem einen oder anderen vielleicht etwas übertrieben, aber ein Namensschema ist ein klarer Vorteil und hilft Ihnen in vielen anderen Fällen. So können Sie beispielsweise einen Namen wie „Uplink MPLS 10 Mbit“ für weitere Schwellenwerte bezüglich der Bandbreitennutzung verwenden. Dies soll aber nicht Teil dieses Artikels sein.
Für den Fall, dass Sie nicht weiter kommen oder eine einfachere Möglichkeit finden, freuen wir uns Ihre Meinung zu hören. Lassen Sie uns an Ihrer Erfahrung teilhaben.
Und zum Abschluss möchte ich noch etwas zu Fehlerraten sagen: Ändern Sie nicht die eingebauten Fehler-Schwellenwerte von 0,01 auf 0,1 Prozent. Dadurch werden Ihnen Probleme aufgezeigt, die Ihnen vorher nicht bewusst waren. Wenn Fehler auftreten: spüren Sie diese auf und beheben Sie diese. Es gibt nur bei WLAN Access Points einen Grund, den Schwellenwert hochzusetzen. Da es sich bei WLAN um ein geteiltes Medium handelt, teilt sich dieser das WLAN mit dem benachbarten Access Point mit der Mikrowelle und Sonneneruptionen. Daher kann es hier Sinn machen, den Schwellenwert zu erhöhen.
Happy monitoring!