Monitoring mit SNMP: Troubleshooting im Gott-Modus
 on 14.07.2020
on 14.07.2020
Hinweis: Der Inhalt dieser Seite verwendet noch die früheren Namen der Checkmk-Editionen. Checkmk Enterprise heißt jetzt Checkmk Pro.
Das Netzwerk-Monitoring mit SNMP funktioniert nicht immer reibungslos. Dies ist häufig darauf zurückzuführen, dass viele Hersteller das Protokoll eher schlecht als recht in ihre Geräte implementieren. Wir haben in unserem letzten Blogpost bereits aufgezeigt, welche Probleme für das Monitoring dadurch entstehen können. Mögliche Anzeichen dafür können sein, dass der Service Check_MK den Status CRIT hat, Sie einen Timeout beim Inventarisieren erhalten oder Checkmk Services, die eigentlich vorliegen sollten, nicht erkannt werden.
In diesem Artikel werden wir uns dem Troubleshooting von typischen SNMP-Problemen widmen – und zwar im sogenannten Gott-Modus. Dies bedeutet jedoch auch, dass Sie vorsichtig agieren müssen. Falsch umgesetzt, lösen Sie damit nämlich nicht das Problem, sondern fahren Ihr Monitoring womöglich ganz vor die Wand oder lösen gefährliche Bugs in den Geräten aus. Wir setzen in diesem Artikel voraus, dass Sie bereits über fundierte Checkmk-Kenntnisse verfügen. Daher erklären wir in diesem Artikel auch nicht die Arbeitsweise des cmk-Kommandos. Eine ausführliche Erklärung finden Sie in der Dokumentation.
Wichtig: Begrenzen sie beim Debugging die Einstellungen und Kommandos immer nur auf das betroffene Gerät. Alle hier nachfolgend aufgeführten Regeln und Konfigurationen sollten sie demnach NUR auf den betroffenen Hosts und mit Bedacht anwenden.
Der Blogpost ist folgendermaßen aufgebaut:
TL;DR:
Der Artikel zeigt, wie Sie typische SNMP-Probleme in Checkmk im „Gott-Modus“ debuggen – also mit tiefem Zugriff auf SNMP-Mechanismen. Dabei ist Vorsicht oberstes Gebot, da falsche Einstellungen das Monitoring stören oder Gerätefehler auslösen können.
- Der Artikel richtet sich an erfahrene Checkmk-Nutzer; grundlegende Befehle wie „
cmk“ werden vorausgesetzt. - Alle Debugging-Schritte dürfen nur auf dem betroffenen Host ausgeführt werden – nie global anwenden.
- Inhaltlich behandelt der Artikel:
- Nutzung des „
cmk“-Kommandos als Debugging-Grundlage - Unterschied zwischen Inline-SNMP und net-snmp
- Optimierung der Bulk size für SNMP-Abfragen
- Einfluss von Timing-Parametern und Timeouts
- Schrittweises „Verlangsamen“ der Abfragen, um fehlerhafte Geräte zu stabilisieren
- Ausschalten von Inline-SNMP als mögliche Lösung
- Nutzung des „
Debugging-Grundlagen: das "cmk"-Kommando
Die Funktionen des „cmk“-Kommandos setzen wir als bekannt voraus, möchten jedoch hier die Kombination mit dem Unix Kommando „time“ hervorheben. Diese Kombination werden wir an einigen Stellen benutzen, um diverse Laufzeitprobleme zu erkennen. Beispielsweise kann man mit Hilfe des Befehls time cmk -Iv HOSTNAME die Gesamtlaufzeit der Discovery-Phase eines Hosts ermitteln:
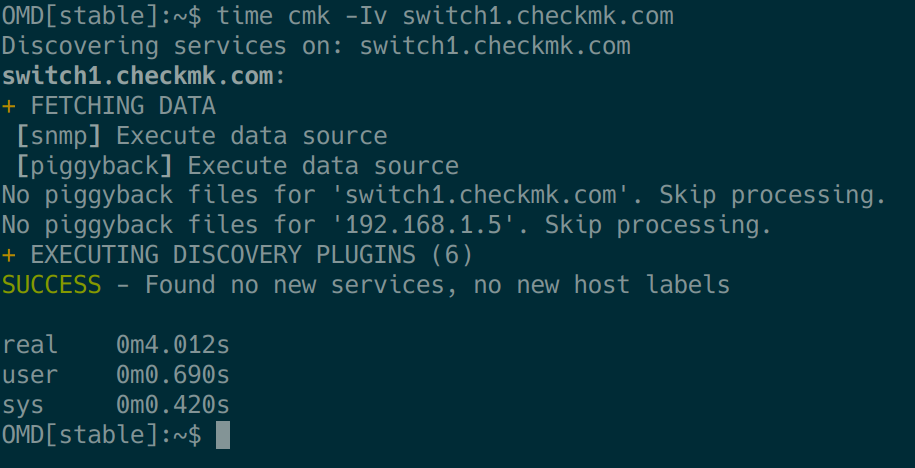
Analog dazu besteht die Möglichkeit, mittels time cmk -nv HOSTNAME die Ausführungszeit für die Abfrage der gefundenen Services zu überprüfen.
Noch weitergehende Informationen erhalten Sie durch die Verwendung von zwei „v“, also zum Beispiel cmk -Ivv HOSTNAME oder cmk -nvv HOSTNAME. Auf diese Weise können Sie unter anderem die gerade abgefragten OIDs einsehen und so beispielsweise langsame OID-Bereiche erkennen, die möglicherweise bis hin zu Timeouts führen können.
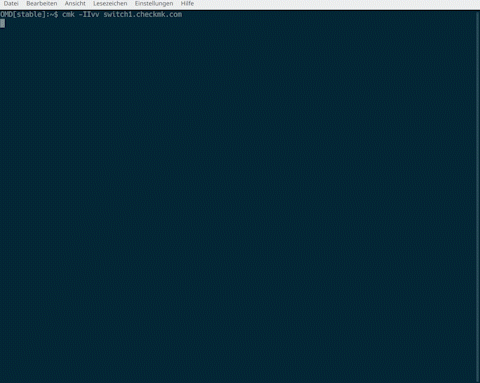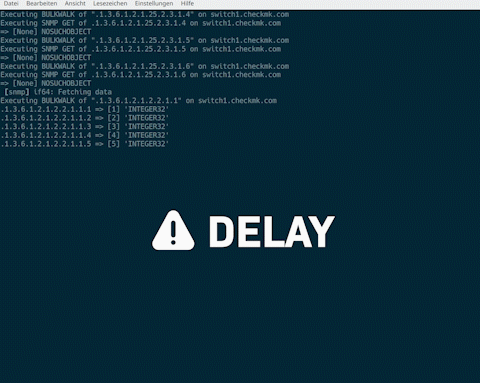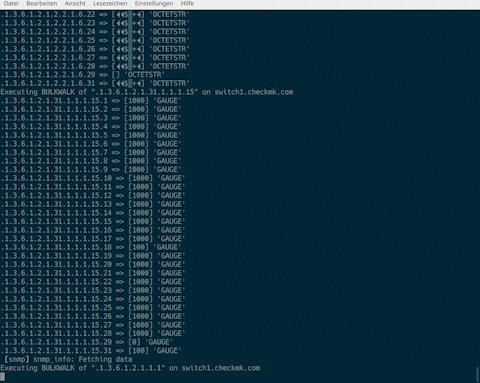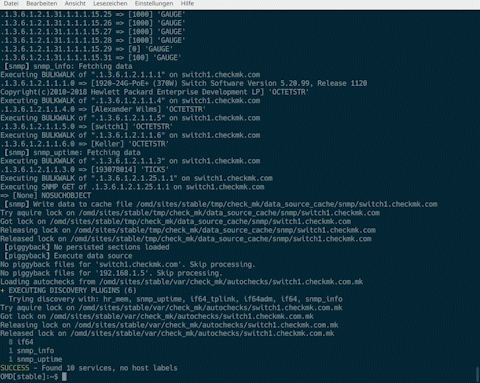
Die so gemessene Gesamtlaufzeit für die Abfrage (-n) beziehungsweise die Discovery (-I/II) sollte aus mehreren Gründen deutlich unter 60 Sekunden liegen. Schließlich beträgt der Standard-Timeout des Services „Check_MK“ 60 Sekunden und müsste daher, zusammen mit einem passenden Check-Intervall, erhöht werden. Zudem blockiert eine länger laufende Anfrage einen Checkmk-Hilfsprozess für diesen Zeitraum.
Vorsicht: Der Befehl cmk -II auf der CLI entsprecht dem „Tabula rasa“ in der GUI. Das heißt, dass die Anwendung nicht ganz ungefährlich ist. Sie sollten daher bei diesem Kommando immer den konkreten HOSTNAME mit angeben, da ansonsten ein Tabula rasa auf die gesamte Instanz ausgeführt wird! (cmk -IIvv switch1.checkmk.com und nicht cmk -IIvv).
Bedenken Sie außerdem, dass sich die Befehle immer nur auf die zuständige lokale Instanz eines verteilten Monitorings beziehen. Sie müssen das Kommando also auf der Instanz ausführen, auf der Sie den Host überwachen.
Debugging-Grundlagen: Inline-SNMP versus net-snmp
Checkmk benutzt seit Version 1.4 Inline-SNMP. Das bedeutet, dass wir in der Standarteinstellung nicht mehr die Kommandozeilen-Tools des net-snmp-Pakets verwenden, sondern die SNMP-Abfrage über ein Python-Modul durchführen. Dies hat den entscheidenden Vorteil, dass wir nicht mehr für jede OID-Abfrage einen eigenen net-snmp-Prozess starten und wieder beenden müssen. Je nach Menge der überwachten SNMP-Geräte sorgt die Nutzung von Inline-SNMP für eine Reduktion der CPU-Last von mehr als 50 Prozent.
Mittlerweile ist Inline-SNMP in den allermeisten Fällen die Einstellung der Wahl und funktioniert zuverlässig mit dem absoluten Großteil der überwachten Hosts. Es sind jedoch Einzelfälle bekannt, bei denen man Inline-SNMP für einen einzelnen Host ausschalten musste – darauf gehen wir aber an anderer Stelle noch einmal ausführlicher ein.
Im Kontext dieses Artikels werden wir Inline-SNMP aus einem anderen Grund – nämlich zu Diagnosezwecken – und auch nur temporär für einen zu analysierenden Host ausschalten:
Im ausgeschalteten Zustand können wir bei der Benutzung der "cmk-Ivv/IIvv/nvv“-Kommandos das korrespondierende net-snmp-Kommando sehen und für weitere Aktionen mittels Copy and Paste weiterverwenden.
Beispielsweise bekommen wir bei einem cmk-Ivv HOSTNAME folgende Ausgabe

und können uns damit beispielsweise das Kommando ‘snmpbulkwalk -Cr10 -v2c -t 1 -c public -m "" -M "" -Cc -OQ -OU -On -Ot 192.168.1.5 .1.3.6.1.2.1.2.2.1.1’ kopieren, weiterbenutzen und gegebenenfalls zur weiteren Analyse modifizieren.
Zu erreichen ist die Regel via: WATO ➳ Host & Service Parameters ➳ Access to agents ➳ Hosts not using Inline-SNMP.
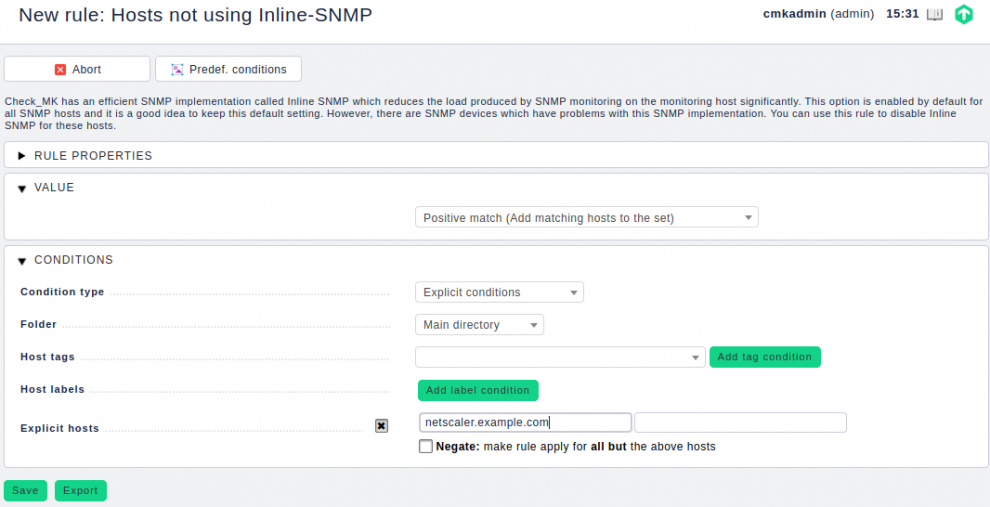
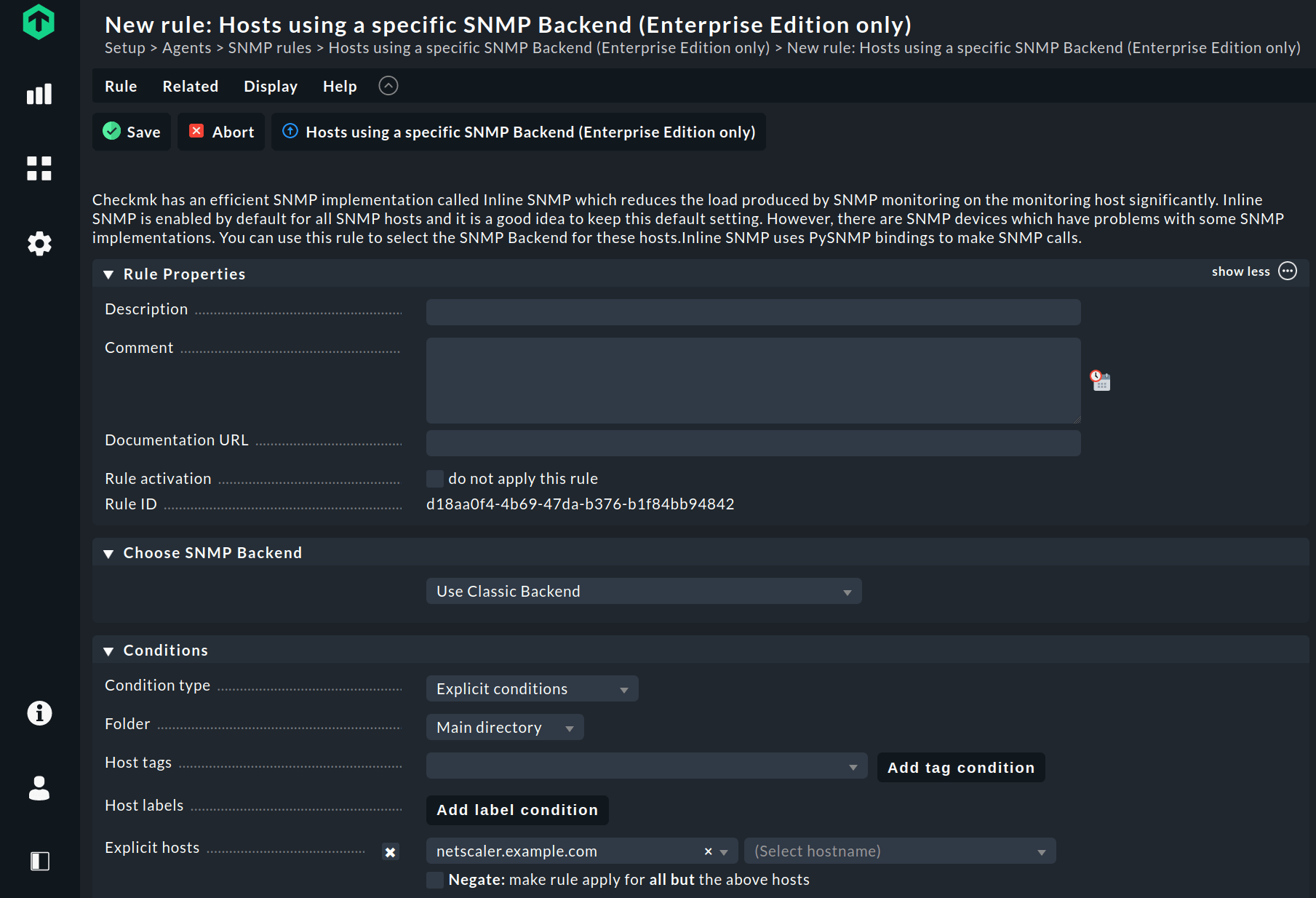
Unter Checkmk 2.0 finden Sie die benötigte Regel, indem Sie im Setup-Menü nach "Backend" suchen. Unter SNMP rules legen Sie nun die Regel Hosts using a specific SNMP Backend (Checkmk Enterprise only) an. In der Regel fügen Sie nun unter Explicit hosts den Host zu und wählen unter Choose SNMP Backend die Option Use Classic Backend aus.
Bulk size – auf die Größe kommt es an
Wir haben in unserem ersten Artikel über das Netzwerk-Monitoring mit SNMP unter anderem dargelegt, dass SNMPv2c und v3 gegenüber v1 den Vorteil haben, dass man OIDs nicht nur einzeln via snmpget abrufen, sondern via snmpbulkget beziehungsweise snmpbulkwalk ganze OID-Bereiche in einem Rutsch abfragen kann. In Checkmk sind standardmäßig 10 OIDs als „Bulk size“ voreingestellt. Dies hat den entscheidenden Performance-Vorteil, dass die Monitoring-Instanz statt zehn einzelnen Anfragen an das Gerät nur eine Anfrage ausführen muss. Dies senkt im Normalfall die erzeugte Last – sowohl auf dem überwachten System als auch auf dem Monitoring-Server selbst.
Es kann immer wieder passieren, dass bestimmte Geräte Probleme mit der vorgegebenen Bulk size von 10 haben und dadurch der SNMP-Stack des Geräts bei einer Bulk size größer als zum Beispiel 8 an einer bestimmten Stelle einfach abstürzen kann. Dadurch ist die Abfrage unvollständig und Services lassen sich nicht mehr erkennen beziehungsweise abfragen.
Es kann aber ebenso vorkommen, das die Gesamtlaufzeit einer SNMP-Abfrage sehr lange dauert und zum Beispiel die Abfrage eines größeren Switches nahe an den Standard-Timeout von 60 Sekunden herankommt oder sogar darüber liegt. In diesem Fall kann es sinnvoll sein, die Bulk size deutlich zu erhöhen, zum Beispiel auf 60. Das Hochsetzen der Bulk sizes, obwohl es eigentlich effizienter ist, kann jedoch den gegenteiligen Effekt haben und die Gesamtlaufzeit nach oben treiben. Wie man sieht, bewegt man sich hier in einem Minenfeld. Apropos Minenfeld: Wir haben es auch schon erlebt, dass ein Core-Switch bei einer zu großen Bulk size komplett crasht und neu startet!
Wichtig: Wir können an dieser Stelle keine allgemeingültige Bulk size nennen, die definitiv funktioniert. Wie so häufig kommt dies auf das jeweilige Gerät drauf an. Für die Lösung des Problems ist also eine gewisse „Fummelei“ nötig. Das heißt, Sie müssen mit den Werten ein wenig herumspielen, bis das Problem nicht mehr auftritt und die Abfrage die Gesamtlaufzeit im Idealfall nicht hochtreibt.
Um uns also weiter an das Problem heranzutasten, begeben wir uns – wie bereits im Abschnitt Debugging Grundlagen: das „cmk“-Kommando beschrieben – auf die Kommandozeile. Als erstes sollten wir uns mit cmk -IIv HOSTNAME anschauen, was überhaupt gefunden wird:
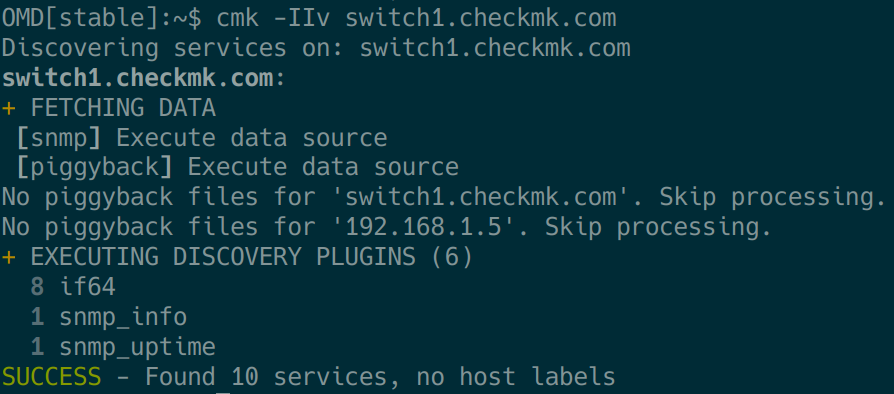
Sollten hierbei Fehler auftreten, können wir nun den Befehl cmk -IIvv mit dem zweiten „v“ auf einen noch gesprächigeren Modus umschalten und – wie bereits oben im Video zu sehen ist – dadurch langsame oder nicht erscheinende OIDs erkennen.
Ein möglicher Grund kann wie erwähnt die Bulk size sein. Wenn wir also einen Bereich identifiziert haben und Inline-SNMP – wie im Abschnitt Debugging-Grundlagen: Inline-SNMP vs. net-snmp erklärt – deaktiviert haben, können wir die betroffene OID beziehungsweise den OID-Bereich gezielt analysieren und den Schalter für die Bulk size (-Cr10) mit kleineren oder größeren Werten manipulieren, bis wir den idealen Wert finden. Für eine Bulk size von --Cr24 sieht das Ergebnis bei uns beispielsweise so aus:
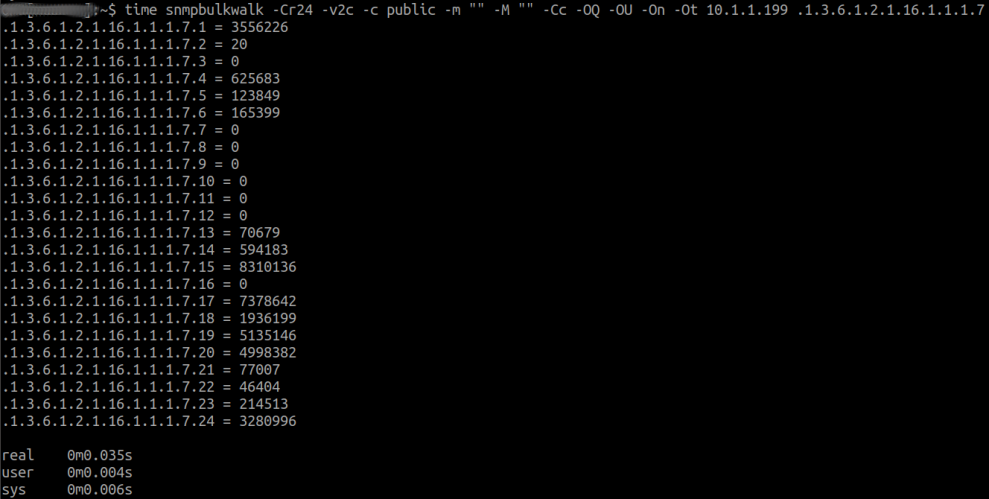
Wenn wir eine funktionierende Parameter-Kombination herausgearbeitet haben, müssen wir diese in WATO-Regeln hinterlegen. Dazu benötigen wir unter Host & Service Parameters ➳ Access to Agents die Regel Bulk walk: Number of OIDs per bulk. In der gleichnamigen Sektion lässt sich die Bulk size nun anpassen:
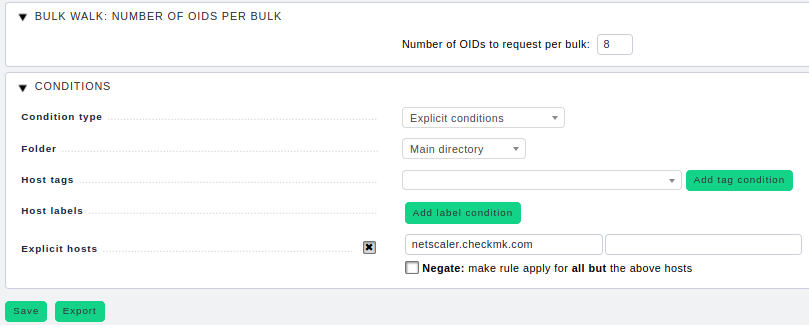
Auch hier gilt: Wenn Sie diese Regel anlegen, darf diese nur für den oder die betroffenen Hosts gelten. Wenden Sie diese niemals auf das Gesamt-Monitoring an!
Nach Anlage dieser Regel und Aktivierung der Konfiguration müssen wir nochmals mit den zugehörigen cmk-Kommandos prüfen, ob die durchgeführten Änderungen zum gewünschten Ergebnis führen, also sich die fehlenden Services nun abfragen lassen.
Timing ist alles
Abgesehen davon kommt es regelmäßig vor, dass ein kompletter SNMP-Stack sehr langsam ist oder überhaupt nur einzelne OID-Bereiche reagieren. Berühmt-berüchtigt sind zum Beispiel die Temperatursensoren von Cisco SFPs, die sich mit dem Check cisco_temperature.dom abfragen lassen. Mitunter benötigt die Abfrage dieser OIDs deutlich länger als eine Sekunde pro OID (Geräteabhängig sogar bis zu sieben Sekunden). Standardmäßig ist Checkmk aber so eingestellt, dass es sowohl mit eingeschaltetem als auch mit ausgeschaltetem Inline-SNMP einen Timeout pro OID von einer Sekunde hat. Ein Timeout von einer Sekunde bei fünf Retries entspricht übrigens auch den Standardeinstellungen des net-snmp-Paketes.
Dies führt natürlich dazu, dass solch langsame OIDs die Gesamtlaufzeit der SNMP-Abfrage deutlich verlängern: 1(s) * 5(Retries) * x Sensoren.
Bei zum Beispiel 120 Sensoren und einer Bulk size von 10 haben wir somit schon eine Gesamtlaufzeit von circa 60(!) Sekunden – ohne dass wir die Temperatursensoren überhaupt discovern können, da wir ja einen Timeout bekommen. Bei diesem Beispiel erreichen wir sogar den Default-Timeout des Check_MK-Checks selbst, sodass wir in einen Gesamt-Timeout laufen. Das führt dazu, dass wir entweder nichts mehr „discovern“ können oder bereits discoverte Services bereits wieder veraltet sind. (Dies ist ein sehr theoretisches Beispiel zur Veranschaulichung. Die Praxis hat deutlich mehr Komplexität zu bieten.)
Wir können nun natürlich die snmpbulkwalk-Kommandos benutzen und uns über den Timeout-Schalter (-t) an die Timeout-Werte herantasten. Dadurch können Sie im Nachgang unter WATO ➳ Host & Service Parameters ➳ Access to Agents die Regel Timing settings for SNMP access mit den entsprechenden Werten anlegen.
Dabei sollten Sie allerdings folgende Dinge bedenken:
- Die Werte gelten pro OID beziehungsweise pro OID-Range im Falle eines snmpbulkget.
- Das Problem multipliziert sich aus: x Sekunden Timeout * Anzahl betroffene OIDs * eingestellte Retries.
- Wie wirken sich die obigen Einstellungen auf die Gesamtlaufzeit aus?
- Erreiche ich damit möglicherweise das Gesamt-Timeout?
- Kann die Monitoring-Instanz dann noch minütlich prüfen? Hinweis: Check_MK/Check_MK-Discovery-Timeout ≤ Check-Intervall
- Wie viele Checkmk-Hilfsprozesse blockiere ich damit? Schließlich blockiert jedes betroffene Gerät einen solchen „Helper“ während eines langsamen Checks.
Ist es unter Berücksichtigung all dieser Aspekte gegebenenfalls sinnvoller, auf diese langsamen OIDs beziehungsweise Checks zu verzichten?
Mach mal langsam...
An die benötigten Timing Settings können Sie sich herantasten, indem Sie den Parameter -t aus dem oben beispielhaft ermittelten Kommando modifizieren und ihn beispielsweise auf sieben (-t 7) Sekunden setzen:
’snmpbulkwalk -Cr10 -v2c -t 7 -c public -m "" -M "" -Cc -OQ -OU -On -Ot 192.168.1.5 .1.3.6.1.2.1.2.2.1.1’
Haben Sie auf diese Weise einen Timeout-Wert ermittelt, der es erlaubt, die oben genannten SFP-Temperatursensoren zuverlässig auszulesen, schlagen Sie zur Sicherheit noch eine zusätzliche Sekunde auf. Die dafür erforderliche Regel Timing settings for SNMP access lässt sich über WATO ➳ Host & Service Parameters ➳ Access to Agents konfigurieren.
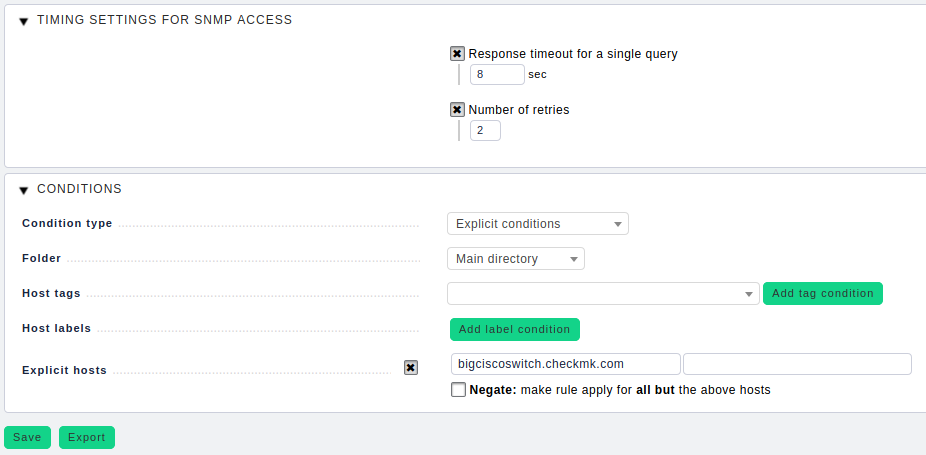
Und auch hier gilt: Diese Regel darf nur auf die betroffenen Hosts angewandt werden und niemals auf das gesamte Monitoring! Es kann nämlich vorkommen, dass SNMP-Implementierungen am Ende eines OID-Zweigs kein „NO SUCH OID“ signalisieren, sondern schlichtweg gar nicht antworten. Dies ist ein klarer Protokollverstoß seitens des Herstellers und führt in Kombination mit langen Timeouts dazu, dass solche Abfragen plötzlich Ewigkeiten dauern und ohne Not zu Gesamt-Timeouts führen. Sprich: Wir warten viel zu lange darauf, dass etwas kommt, und wissen dabei nicht, dass nichts kommen wird.
Das gleiche Prinzip gilt auch für die Retry-Rate. Es ist unwahrscheinlich, dass es neunmal keine Antwort gibt, die zehnte Anfrage jedoch plötzlich beantwortet wird. Daher sollten Sie die Anzahl der Retries entsprechend klein wählen und beispielsweise auf zwei oder drei Versuche begrenzen. Besser ein schnelles Ende durch ein Timeout als Timeouts ohne Ende...
... noch langsamer...
Sollten wir es mit den obigen Einstellungen geschafft haben, dass die Werte abfragbar sind – prima! Ungünstig wird es, wenn wir uns jetzt dem Gesamt-Timeout von 60 Sekunden nähern oder dieses sogar überschreiten. In diesem Fall müssen wir den Gesamt-Timeout für die entsprechenden Services anpassen. Dies können wir über die folgende Regel beeinflussen: WATO ➳ Host & Service Parameters ➳ Monitoring Configuration ➳ Service check timeout (Microcore).
Die beiden relevanten Services geben wir in den Conditions vor mit Check_MK$ und Check_MK Discovery$.
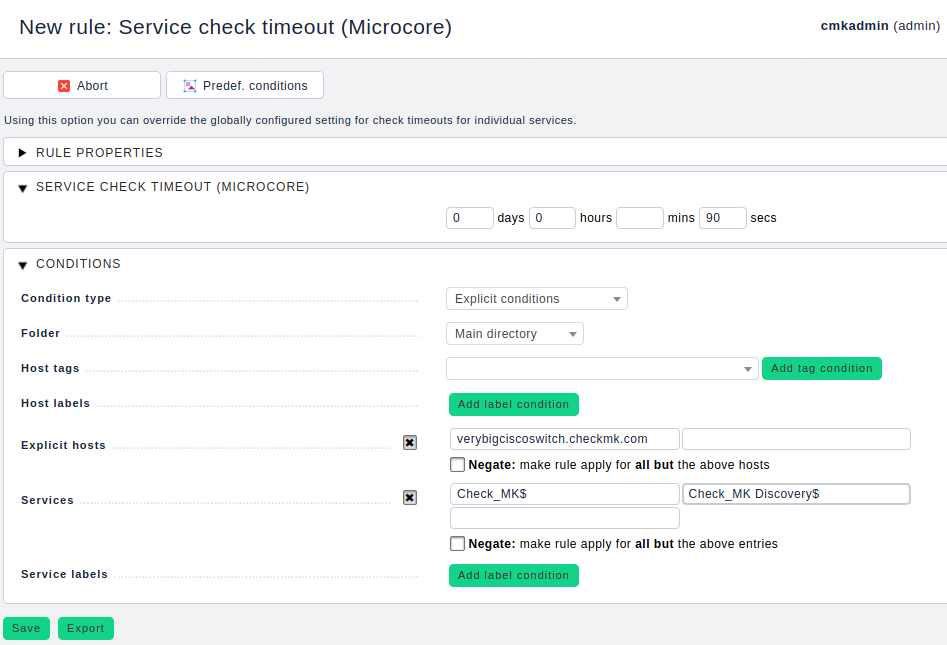
Wie bereits erwähnt sollten Sie das Check-Intervall passend setzen, etwa auf zwei Minuten (Timeout ≤ Intervall). Ansonsten werden die Services „stale“, da diese sich erst später prüfen lassen, als durch die Konfiguration eigentlich vorgesehen ist. Gehen Sie dazu auf WATO ➳ Host & Service Parameters ➳ Monitoring Configuration ➳ Normal check interval for service checks.
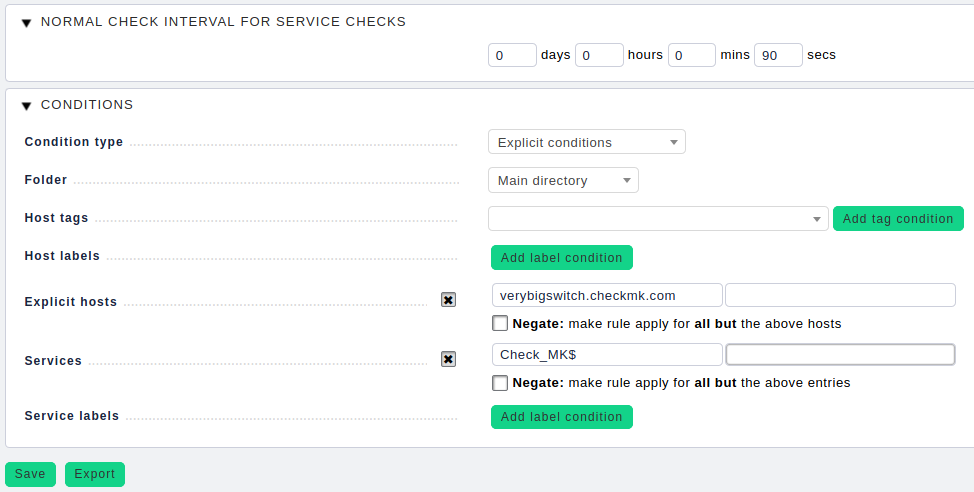
Wichtig ist hierbei der Hinweis in der Regelbeschreibung, dass diese Regel nur auf den Service Check_MK und nicht etwa auf Check_MK Discovery oder Check_MK HW/SW Inventory angewandt wird. Letztere haben nämlich ein Standard-Check-Intervall von zwei beziehungsweise 24 Stunden und würden eine erhebliche Last erzeugen, sollten sie mit einem zwei Minuten Intervall laufen. Deshalb ist es essentiell, dass Sie den Ausdruck Check_MK$ in der Services Condition nutzen.
Wichtig: „$“ ist der reguläre Ausdruck (Regexp) für String-Ende. Das heißt, dass das Suchmuster Check_MK$ nur auf Check_MK matcht. Dadurch stellen Sie sicher, dass die Regel nicht auf Check_MK-Discovery oder Check_MK HW/SW Inventory angewandt wird, wie es bei dem Suchmuster Check_MK (ohne $ - Infix Suche) der Fall wäre.
Und auch an dieser Stelle gilt: Wenn Sie diese Regeln anlegen, dürfen diese nur für den oder die betroffenen Hosts gelten. Wenden Sie diese niemals auf das Gesamt-Monitoring an!
... oh, nun ist es zu langsam!
Sollten Sie jetzt aber zu der Erkenntnis kommen, dass Sie den Switch doch lieber häufiger als nur alle zwei oder sogar nur alle zehn Minuten abfragen wollen und dass Ihnen die langsamen Temperatursensoren eher verzichtbar erscheinen – dann können Sie den entsprechenden Check deaktivieren. Das ist mitunter die bessere Wahl. Die nötige Regel befindet sich unter: WATO ➳ Host & Service Parameters ➳ Monitoring Configuration ➳ Disabled checks.
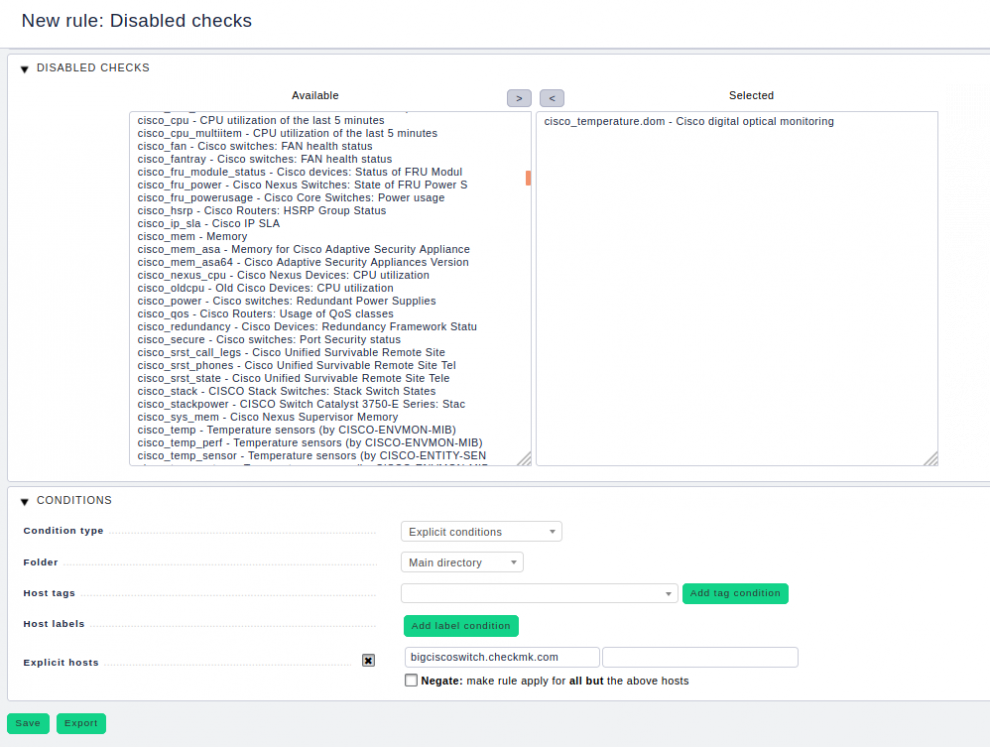
Sie wissen es schon, der Autor wiederholt sich zwar ungern, aber es muss sein: Wenn Sie diese Regeln anlegen, dann dürfen diese nur für den beziehungsweise die betroffenen Hosts gelten. Wenden Sie diese niemals auf das Gesamt-Monitoring an! Einzige Ausnahme: Sie möchten die Services auf keinem Ihrer Geräte sehen – obwohl diese ausnahmsweise auch mal schnell sein könnten.
An dieser Stelle sei außerdem noch kurz der Hinweis erlaubt, dass das Deaktivieren von einzelnen Services über eine Regel vom Typ „Disabled Services“ für diesen Anwendungsfall keine wirksame Alternative darstellt. Solange man auch nur einen Sensor abfragt, wird der gesamte Check ausgeführt, unter anderem auch wegen der Bulk size.
Inline-SNMP ausschalten als Lösung
Zu guter Letzt sei noch erwähnt, dass es in manchen Fällen notwendig sein kann, Inline-SNMP für bestimmte Hosts auszuschalten. Wir hatten beispielsweise den Fall, dass ein Gerät die eigentlich mit jeder Antwort hochzuzählende SNMP-Sequenznummer zuverlässig und stoisch mit einer 1 befüllte. Dies ist ein weiterer klarer RFC-Verstoß und das Python-SNMP-Modul hat diese Pakete konsequenterweise abgelehnt. Die Kommandozeilen-Tools des net-snmp-Pakets störten sich jedoch nicht daran, sodass wir dem Kunden durch eine – Sie wissen es schon – granulare Regel für diesen einen Host helfen konnten. Nachhaltiger – aber mit weniger Spaß verbunden – wäre natürlich ein Ticket beim Hersteller.
Fazit
Wie wir gesehen haben steht das „S“ in SNMP zwar für „simple“, dies gilt jedoch nur, wenn der Hersteller auch alle RFC ordentlich und sauber implementiert hat. Falls nicht, wird es schnell beliebig kompliziert mit zahlreichen, teilweise ineinandergreifenden oder auch unerwartet kontraproduktiven Einstellungen. Und dabei haben wir SNMPv3-Kontexte und ähnlich spannende Dinge in diesem Artikel noch nicht einmal gestreift. Dennoch hoffen wir, dass wir Ihnen mit dieser Anleitung zum Troubleshooting helfen konnten, mögliche SNMP-Probleme in Ihrer Monitoring-Umgebung zu erkennen und zu beheben.
Im nächsten und letzten Teil unserer Serie Netzwerk-Monitoring mit SNMP wollen wir einen Ausblick auf die künftige Entwicklung des SNMP-Monitorings wagen und auf mögliche Nachfolger eingehen. Oder wird uns SNMP auch die nächsten 30 Jahre noch erfreuen?