Linux-Memory-Monitoring: RAM oder Swap?
 on 04.06.2020
on 04.06.2020
TL;DR:
Die Linux-Speicherüberwachung erfordert eine gemeinsame Betrachtung von RAM und Swap, um die Systemleistung realistisch einzuschätzen und Fehlalarme zu vermeiden.
- Swap wird vom Kernel proaktiv zur Cache-Optimierung genutzt. Eine hohe Swap-Nutzung bedeutet daher nicht automatisch ein Problem.
- Die Überwachung des gesamten Speicherverbrauchs, einschließlich Puffer und Caches, vermittelt ein tatsächliches Bild der Systemauslastung und verhindert falsche Rückschlüsse aus isolierten RAM- oder Swap-Werten.
- Erweiterte Kennzahlen wie dirty blocks und page tables helfen dabei, versteckte Speicherlast oder I/O-Probleme zu erkennen, die einfache Tools häufig übersehen.
Linux ist raffinierter, als man denkt
Meine Erfahrungen mit dem Überwachen von Speicher unter Linux reichen schon weit zurück. Begonnen hat eigentlich alles im Jahre 1992. Linux installierte man damals noch von Disketten, es konnte kein TCP/IP und die Versionsnummer fing mit 0.99 an. Genau genommen war die Sache mit dem Speicher sogar der Grund, warum ich damals überhaupt auf Linux aufmerksam wurde. Ich bin bei der Programmierung meines ersten größeren Projekts in C++ (ein Spiel, das per Post gespielt wurde!) bei MS-DOS an die Grenzen des RAMs gestoßen. Linux glänzte hingegen mit einer modernen Speicherarchitektur, die einen linearen Adressraum bot und sich durch Swap quasi unbegrenzt erweitern lies. Einfach nur programmieren, ohne über Speicher nachdenken zu müssen. Genial!
Das erste Tool zu Überwachung war auch damals schon der Befehl free, den fast jeder Linuxer kennt. Er zeigt den aktuellen "Verbrauch" von RAM und Swap an:
mk@Klapprechner:~$ free
total used free shared buff/cache available
Mem: 16331712 2397504 9976772 222864 3957436 13369088
Swap: 32097148 553420 32097148
Natürlich waren die Zahlen damals noch nicht so groß – wir lesen hier KBytes, nicht Bytes – und mein Rechner hatte nicht 16 GByte, sondern gerade mal 4 MByte! Aber schon damals war das Prinzip das gleiche. Und schon damals war die Furcht vor intensivem Swap-Verbrauch und der damit verbundenen Performance-Einbuße groß. Aus diesem Grund sollte jedes vernünftige Monitoring-System sowohl einen Check für den RAM-Verbrauch als auch einen für den Swap haben.
So dachte ich zumindest – bis ich mir im Rahmen der Entwicklung von Checkmk fast 20 Jahre später die Sache einmal genauer angesehen habe: Natürlich war schon klar, dass man Buffer und Caches quasi als freien Speicher werten kann. Und das machen ja (fast) alle Monitoring-Systeme sozusagen richtig. Aber ich wollte es genauer wissen und habe gründlich die Bedeutung aller Angaben in /proc/meminfo recherchiert. Denn in dieser Datei gibt der Linux-Kernel genau Auskunft über alle aktuellen Parameter der Speicherverwaltung. Und hier gibt es viele Informationen – weit mehr als free anzeigt. Teilweise musste ich bis in den Quellcode von Linux vorstoßen, um die Zusammenhänge genau zu verstehen.
Ich kam dabei zu überraschenden Ergebnissen, welche – ja, so kann man das wahrscheinlich sagen – die Grundfesten meines Weltbildes erschütterten:
- Die Speicherverwaltung von Linux ist viel raffinierter und ausgefeilter, als ich dachte. Die Worte "frei" und "belegt" greifen da überhaupt nicht weit genug.
- Swap und RAM getrennt zu betrachten ergibt überhaupt keinen Sinn.
- Und selbst die offensichtliche Idee, Buffer/Caches als frei zu betrachten, ist nicht unbedingt richtig!
- Viele wichtige Parameter zeigt
freeüberhaupt nicht an; sie können aber absolut kritisch sein. - Der Linux-Memory-Check von Checkmk muss komplett überarbeitet werden.
Nach ein paar Tagen Arbeit ist der große Wurf gelungen. Checkmk hat seitdem den – meiner Überzeugung nach – besten, genauesten und vor allem fachlich "am richtigsten" Linux-Memory-Check, den man sich vorstellen kann. Aber dadurch taucht ein neues, viel größeres Problems auf: die Erklärung! Das Check-Plugin arbeitet jetzt in so einem Maße richtig, dass viele Anwender erstmal überrascht und misstrauisch an den Resultaten zweifeln. Und überhaupt: Wie kann es sinnvoll sein, wenn eine Schwelle für RAM über 100 Prozent liegt?
Was ist wertvoller? Prozesse oder Cache?
Sehen wir uns die Sache einmal genauer an. Nehmen wir an, unser Server hat 64 GByte RAM und ebenso viel Swap. Das macht zusammen 128 GByte maximalen Speicher. Und vergessen wir einfach mal die Tatsache, dass auch der Kernel selbst einen Teil des Speichers braucht.
Und jetzt sagen wir, dass wir einen Haufen Anwendungsprozesse haben, die zufällig gerade 64 GByte RAM brauchen. Das klingt wunderbar, denn der Swap-Space sollte nicht gebraucht werden, oder? Hier wartet gleich die erste Überraschung. Denn Linux ist so frech und lagert Teile der Prozesse in den Swap-Bereich aus. Warum macht es das? Der Kernel hätte gerne Speicher für Caches. Denn diese sind nicht nur eine nette Zweitverwendung für sonst leer stehenden Speicher (wie ich früher dachte), sondern absolut kritisch für ein performantes System. Würde Linux wirklich alle Dateien immer wieder von der Platte holen, hätte das eine schlimmere Auswirkung, als wenn ein paar unwichtige Teile von Prozessen im Swap-Bereich landen.
Folgende Grafik zeigt den Verlauf verschiedener Caches eines Servers innerhalb einer Woche. Der meiste Platz wird natürlich für Inhalte von Dateien genutzt (File contents). Aber auch Caches für die Dateisystemstruktur (Verzeichnisse, Dateinamen etc.) haben einmal pro Tag einen immensen Platzbedarf von bis zu 17,78 GByte. Ich habe das nicht näher untersucht, aber es könnte sein, dass um diese Zeit immer eine Datensicherung läuft.
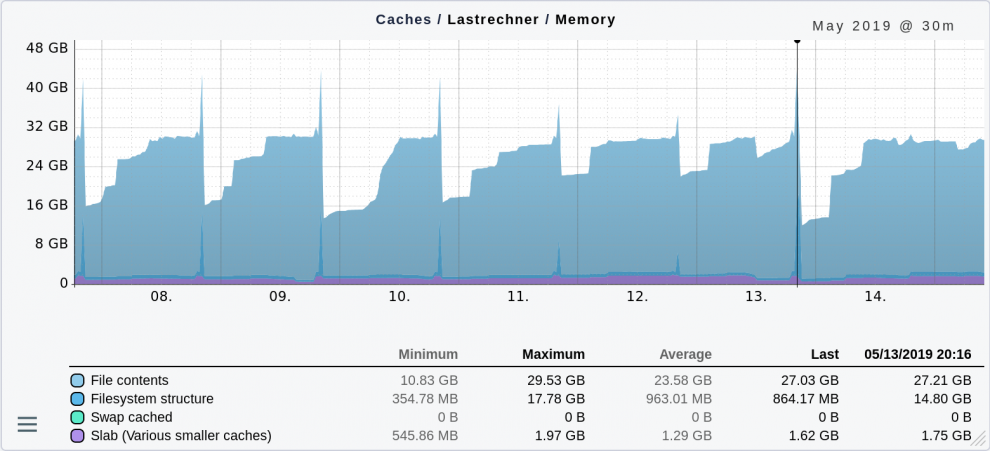
Linux lagert also schon viel früher Teile von Prozessen aus und nicht erst, wenn der Arbeitsspeicher knapp wird. Und das Maß hängt auch noch von äußeren Einflüssen ab. Wenn das System viele unterschiedliche Dateien liest – zum Beispiel bei einer Datensicherung – erweitert es den Cache und lagert Prozesse vermehrt aus. Ist die Sicherung vorbei, bleiben die Prozesse jedoch vorerst im Swap – auch wenn jetzt im RAM wieder Platz wäre. Denn warum sollte man wertvolle Disk-IO-Bandbreite für Daten verschwenden, die man vielleicht nie braucht?
Was heißt das nun für ein sinnvolles Monitoring? Betrachtet man RAM und Swap getrennt, lässt sich feststellen, dass man nach der Datensicherung mehr RAM frei hat als vorher – und dass mehr Swap belegt ist. Aber eigentlich hat sich ja nicht wirklich was geändert. Hat man also zwei getrennte Checks, so zeigen beide einen jeweils umgekehrten Knick in der Kurve, der zu falschen Schlüssen und vor allem zu falschen Alarmierungen verleitet.
Besser ist es, die Summe aus belegtem RAM und Swap zu betrachten. Was bedeutet diese Summe? Sie ist nichts anderes als der gesamte Speicherverbrauch aller aktuellen Prozesse – und zwar unabhängig davon, in welcher Speicherart die Daten gerade liegen. Diese Summe und nichts anderes ist relevant für die Auslastung des Systems.
Ein Schwellenwert über 100 Prozent?
Nun stellt sich natürlich noch die Frage nach einem sinnvollen Schwellenwert für eine Alarmierung. Absolute Schwellenwerte wie zum Beispiel 64 GByte sind natürlich sehr unpraktisch, wenn man eine Vielzahl unterschiedlicher Server überwacht. Aber auf was soll sich ein relativer Wert in Prozent dann beziehen? Aus meiner Sicht ist es am sinnvollsten, diesen ausschließlich auf das RAM zu beziehen. Eine Schwelle von 150 Prozent ergibt dann plötzlich Sinn. Denn diese bedeutet, dass die Prozesse bis zu 50 Prozent mehr Speicher verbrauchen dürfen, als echtes RAM vorhanden ist. So ist sichergestellt, dass immer noch der Großteil der Prozesse im RAM Platz findet – selbst wenn man noch die Caches berücksichtigt.
Weitere interessante Speicherwerte
Wer mal nach /proc/meminfo geguckt hat, war sicher überrascht, wie viele Werte hier stehen und welche Informationen über RAM und Swap hinaus zu finden sind. Und ein paar davon sind durchaus relevant für die Praxis. Davon möchte ich zwei nennen, die mir schon einmal Schwierigkeiten bereitet haben:
Dirty (Filesystem Writeback)
Der Wert "Dirty" umfasst Blöcke aus Dateien, die von Prozessen geändert aber noch nicht auf Platte zurückgeschrieben wurden. Linux wartet mit dem Schreiben von solchen Blöcken in der Regel bis zu 30 Sekunden – in der Hoffnung, weitere Änderungen im gleichen Block effizient zusammenfassen zu können. In einem gesunden, wenn auch stark belasteten System sieht das so aus:
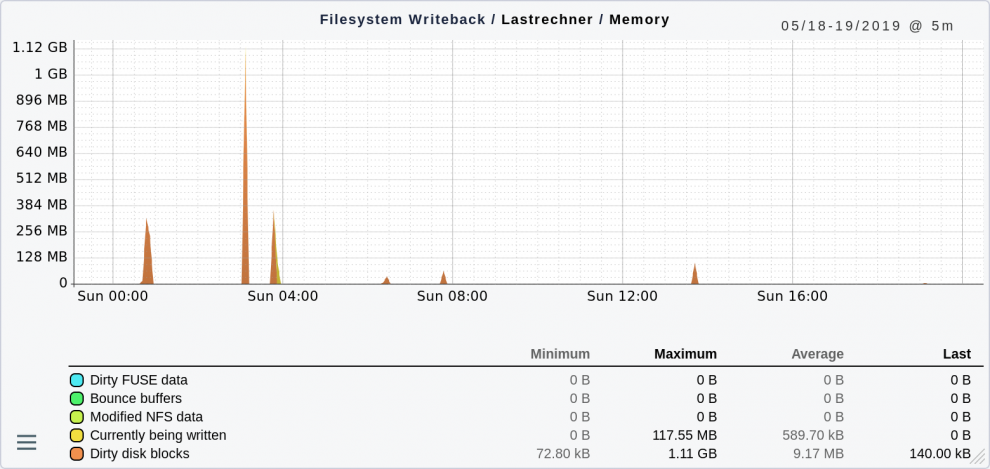
Die einzelnen Spitzen zeigen Situationen, in denen sehr viele Dateien gleichzeitig neu angelegt oder geändert wurden. Das ist noch kein Grund zur Besorgnis, weil Linux diese Daten jeweils sehr schnell weggeschrieben hat. Wenn Sie jedoch eine Situation haben, in der sich dauerhaft ein Stau bildet, bedeutet das in der Regel einen Flaschenhals beim Disk-IO. Das System bekommt die Daten nicht weggeschrieben.
Dafür gibt es einen guten Test: Gehen Sie auf die Kommandozeile und geben Sie den Befehl sync ein. Dieser bricht die 30 Sekunden Wartezeit sofort ab und schreibt alle ausstehenden Daten auf die Festplatte. Das darf nur wenige Sekunden dauern. Hängt der Befehl länger, gibt es Grund zur Sorge. Wichtige geänderte Daten sind nur im RAM und schaffen es nicht auf die Festplatte. Es könnte sich auch um einen Hardwaredefekt im Festplatten-Subsystem handeln. Dauert sync sogar mehrere Stunden, ist höchste Alarmbereitschaft angebracht und es besteht dringender Handlungsbedarf.
Das Überwachen der Dirty disk blocks kann solche Situationen erkennen und rechtzeitig alarmieren.
Pagetables
Jeder Prozess unter Linux hat eine Tabelle, die virtuelle in physikalische Speicheradressen abbildet. Dort steht zum Beispiel auch, wohin Linux im Swap-Space etwas ausgelagert hat. Es versteht sich von selbst, dass diese Pagetables im RAM liegen müssen und sich nicht swappen lassen. Folgender Graph zeigt einen Server, auf dem das Ganze absolut im Rahmen ist:
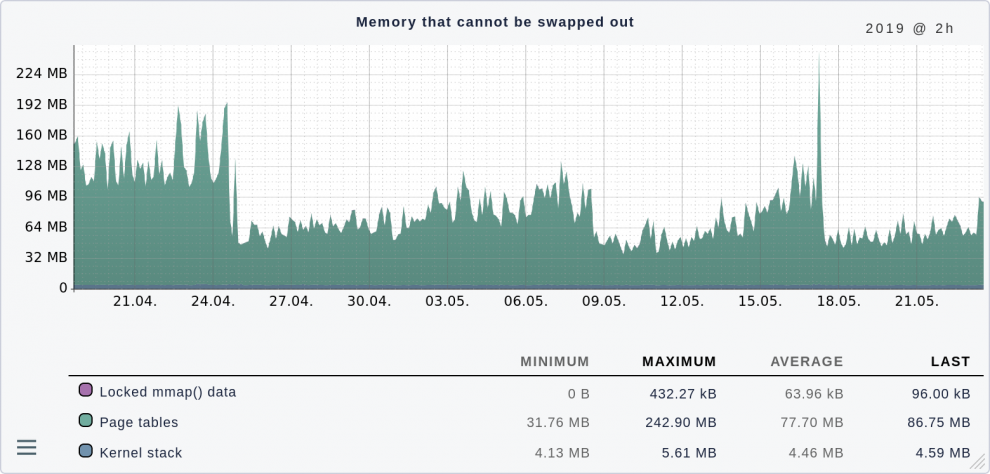
Natürlich sind 240 MByte Maximum nur für diese Tabellen eine Menge Speicher, wenn man bedenkt, dass mein erster Rechner überhaupt nur 4 MByte hatte. Bei 64 GByte RAM insgesamt tut das aber nicht weh.
In meiner Zeit als Linux-Berater hatte ich einen Kunden, der auf einem großen Server viele Oracle-Datenbanken betrieben hat. Die Architektur von Oracle sieht vor, dass viele Prozesse parallel Anfragen an die Datenbank bearbeiten und mit dieser über Shared-Memory kommunizieren. Der Kunde hatte sehr viele dieser Prozesse aktiviert. Nun wird das RAM bei Shared-Memory zwar wirklich nur einmal benötigt, aber eine Pagetable braucht jeder Prozess trotzdem selbst und das Shared-Memory schlägt sich in jeder Tabelle erneut nieder. Diese Tabellen summierten sich auf dem System auf über 50 Prozent des RAMs auf. Das Verwirrende ist zudem, dass dieser Speicher in top oder ähnlichen Tools nicht bei den Prozessen sichtbar ist. Irgendwie ist der Speicher weg, und keiner weiß wohin.
Die Lösung war dann sehr einfach: Man kann bei Linux sogannte Huge Pages aktivieren. Dann verwaltet eine Page nicht mehr 512 Bytes, sondern beispielsweise 2 MByte, wodurch die Tabellen wesentlich kleiner werden. Aber man muss die Ursache erst einmal finden. Daher gehört eine Überwachung der Pagetables zu einem vernünftigen Monitoring.
Zusammenfassung
Speicher-Monitoring ist mehr als ein einfacher Schwellenwert für "belegtes" RAM. Da die Speicherverwaltung bei verschiedenen Betriebssystemen sehr unterschiedlich ist, muss ein gutes Monitoring dessen Eigenheiten kennen und darauf Rücksicht nehmen.