Linux Swap Monitoring: Top Insights from Checkmk
 on Jun 5, 2019
on Jun 5, 2019
TL;DR:
Linux memory monitoring requires looking at RAM and swap together to accurately assess system performance and avoid false alarms.
- Swap is used proactively by the kernel to optimize caches, so high swap usage doesn’t necessarily indicate a problem.
- Monitoring total memory consumption, including buffers and caches, gives a true picture of system load rather than looking at RAM or swap in isolation.
- Advanced metrics like dirty blocks and page tables help detect disk I/O issues and hidden memory usage that simple tools might miss.
The Linux operating system: memory usage and swap monitoring
My experience with how to monitor memory under Linux goes back a long way. It all started in 1992, when Linux was still installed from floppy disks, couldn't handle TCP/IP, and the version number started with 0.99.
Memory was the reason why I became aware of Linux. When I was programming my first significant project in C++ (a game played by physical mail!), I had reached random access memory (RAM) limits in MS-DOS and was in search of a solution. The Linux system featured a modern architecture that offered a linear address space that could be extended virtually indefinitely by swapping. This enabled me to program without thinking about memory. Ingenious, I thought, while discovering how much swap space helped my work!
How to monitor the Linux system in the old school way
The first tool for monitoring memory was the free command, which almost every Linuxer knows. It shows the current “consumption” of random access memory and swap, enabling you to check swap space usage.
mk@Klapprechner:~$ free
total used free shared buff/cache available
Mem: 16331712 2397504 9976772 222864 3957436 13369088
Swap: 32097148 553420 32097148
Of course, the numbers weren't that big back then (we read kB here, not bytes), and my computer didn't have a 16 GB disk space, just 4 MB!
Still, even then, the principle was the same. At that time, the fear of intensive swap space usage and the associated loss of performance was enormous. For this reason, I considered that every decent server monitoring system should have a check for the random access memory consumption and a check for swap space.
Swap usage insights into developing Checkmk
The above is what I thought initially, until I took a closer look at it during Checkmk's development, almost 20 years later! It was pretty clear that buffers and caches can be considered free memory, as that's what (almost) all monitoring systems do.
I wanted to know more about it and thoroughly researched the meaning of all information in /proc/meminfo. In this file, the Linux kernel version gives exact information about all current memory management parameters and swap space.
There is a lot of output here – much more than free shows. In some cases, commands weren't enough. I had to venture into the source code of Linux to understand the connections exactly.
The five premises that enabled us to deliver Checkmk – the most accurate tool to monitor swap space usage
Following the above, I came to surprising results, which you could probably say shook the foundations of my view on how to monitor swap space usage.
- The management of Linux is much more ingenious and sophisticated than I thought. The words “free” and “occupied” don't do justice to what happens.
- Looking at swap space and random access memory separately makes no sense.
- Even the apparent idea of considering buffers/caches as
freeis not necessarily correct! - Many important parameters are not shown for free, but they can be critical for how the system runs.
- Checkmk's Linux memory check needed to be reworked entirely to ensure we monitor swap usage accurately and display information correctly.
After a few days of work, we did it. In my opinion, Checkmk has the best, most accurate, and, above all, most technically “correct” Linux memory check imaginable.
This led to a new, much bigger problem: explaining it! The check plug-in was running processes correctly, working to such an extent that many users were surprised and suspicious of the results.
How does it make sense if a RAM threshold is above 100%?
What's more valuable? Processes or Cache?
Let's take a closer look at this. Our server has 64 GB RAM and just as much swap partition. That makes a total of 128 GB, maximum. And let's just forget the fact that the kernel itself needs some space.
Now, let's assume we have an app or a tool that needs 64 GB of RAM.
That sounds wonderful because swap space usage would be minimal, right? The first surprise: the Linux system is cheeky and outsources parts of the processes to the swap partition. Why? Because the kernel would like to select swap memory for caches. This is not only a nice second use for otherwise empty memory (as I used to think) but critical for a high-performance system.
Without the swap file, things would be very complicated. All files would have to fetch from disk space repeatedly, so the overall effect would be much worse than if a few unimportant parts of processes end up in the swap area.
The following graphic shows the development of different server caches over a week. Most of the space is used for file contents. In this context, a swap file is an excellent solution.
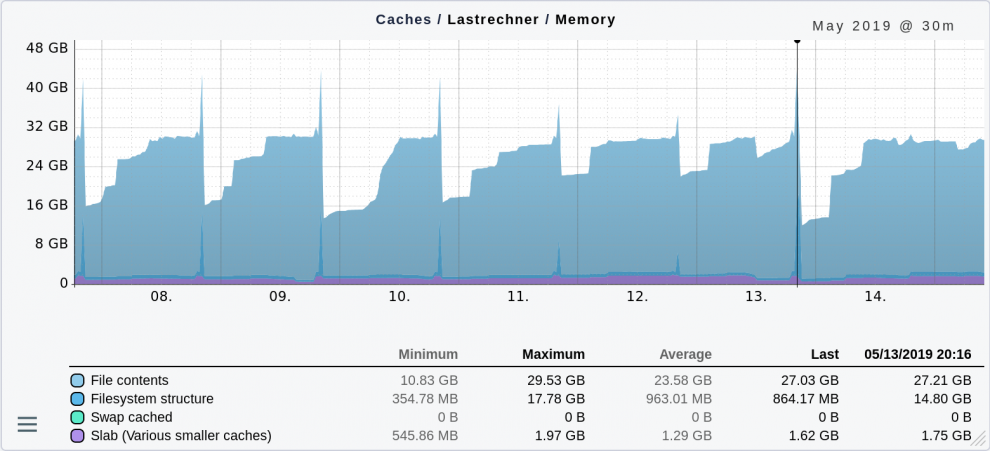
Still, caches for the file system structure (directories, file names) also take up an immense amount of space once a day (up to 17.78 GB). I didn't investigate this further, but it could be that a backup is always running at that time.
External factors influence the Linux system swap space usage
Linux, therefore, uses the swap field much earlier and not only when memory becomes scarce. That extent depends less on the system state and more on external influences.
If many files have been read – e.g., during a data backup – the cache is bloated, and processes are increasingly moved to the swap space.
Once the backup is over, the processes remain in swap areas for some time – even if there is space in RAM again. The reason is simple: why waste valuable disk IO bandwidth for data you might never need?
Swap space and RAM usage should be assessed together
What does the above mean for meaningful monitoring? If you look at RAM and swap usage separately, you will notice that, after the data backup, you have more RAM free than before – and that more swap space is occupied.
In reality, nothing has changed. If you have two separate checks and both show an inverted bend in the curve, it might lead to wrong conclusions and, above all, to false alarms.
It is better to consider the sum of occupied RAM and swap space. What does this mean? It is nothing more than the current total memory consumption of all processes – regardless of where the data is currently stored. This sum and nothing else is relevant to the configuration and performance of the system.
A threshold above 100%?
Now, of course, there is the question of a sensible threshold for an alarm.
Absolute thresholds, such as 64 GB, are, of course, supremely impractical if you monitor many servers following commands. But to what should a relative value in percentage refer?
From my point of view, it makes the most sense to relate this value exclusively to RAM. In this case, a threshold of 150% suddenly makes sense! This means that the processes may consume up to 50% more memory than there is real RAM. The measure ensures that most processes can still be stored in RAM – even if the caches are still considered.
Further interesting memory usage values
If you have ever looked at /proc/meminfo, you were surely surprised by the values output and how much information can be found beyond RAM and swap usage. A few of them relate to quite relevant functions.
I would like to mention two, both of which have created trouble for me:
Dirty (Filesystem Writeback)
The 'dirty' value includes blocks of files that have been modified by processes but not yet written to disk.
Linux usually waits up to 30 seconds to write such blocks, hoping to merge further changes into the same block efficiently. In a healthy, albeit heavily stressed system, this is what it looks like:
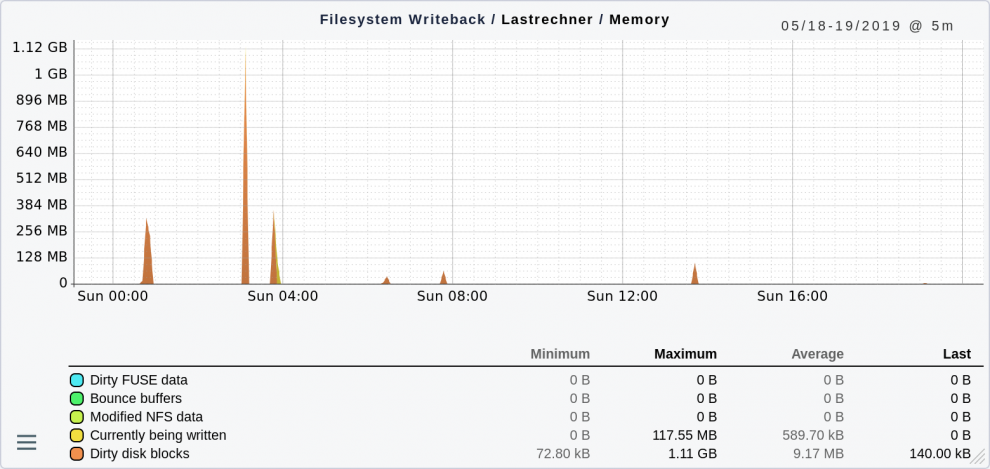
The individual peaks show situations where many new files were created or changed in one sweep. This is no cause for concern because the data was written to disk very quickly.
However, if you have a situation where there is an endless jam, it usually means a bottleneck in the disk IO. The system can't write the data back to disk in time.
There is a good test for this: go to the command line and type the command sync. This immediately aborts the 30 seconds wait and writes all outstanding data to disk. It should only take a few seconds.
If following command lasts longer, there is cause for concern. Necessary modified data is only in the RAM. There is no output to the disk. That could indicate a hardware defect in the disk subsystem.
If sync lasts several hours, you need to ring the alarm bells, and urgent action is required.
Monitoring the dirty disk blocks can detect such system situations and alert you in time.
Paging
Every process under Linux has a table that maps virtual memory addresses to physical memory addresses. This is called paging.
The table also shows, for example, where something has been stored in the swap space. These page tables must be kept in RAM, as swapping isn't possible. The following graph shows a server where everything is absolutely within limits:
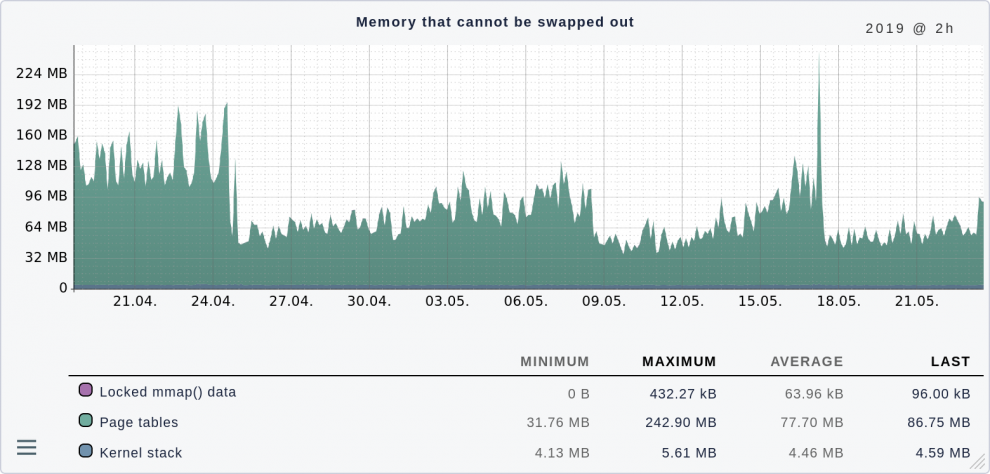
Of course, a maximum of 240 MB is a lot only for these tables, considering that my first computer had only 4 MB. However, with 64 GB RAM in total, this doesn't hurt.
Case study: Oracle database
The premise
As a Linux consultant, I had a customer who was running many Oracle databases on a large server. The architecture of Oracle allows many processes to handle commands to the database in parallel and communicate with it via Shared Memory. The customer had many such commands active.
The situation
The RAM for Shared Memory is really only needed once, but each process needs a Page Table anyway, and the Shared Memory is reflected in each table again.
These tables added up to more than 50% of the RAM on the Linux systems. The confusing thing was that this was not visible in the processes in top or similar tools. Somehow the memory was gone, and nobody knew where it was going!
The solution
The solution was then straightforward: you can activate so-called Huge Pages with Linux systems. A Page no longer manages 512 bytes, but, e.g., 2 MB and the tables become much smaller. But you have to find the root cause first. Therefore, checking Page Tables is crucial for good monitoring.
Conclusion
Memory monitoring is more than just a simple threshold for “used” RAM. Since memory management is very different for each operating system, good monitoring has to know and consider its peculiarities. Swap space is crucial to understanding how the system runs when it comes to Linux.
