Reasons to abandon Nagios
Monitoring IT with Nagios is no longer state-of-the-art. You can read here which criteria you should have for an alternative, and what you should consider if you have decided to switch to another tool.

Often, IT professionals in particular underestimate the benefits of switching to another solution. In fact, time and again Nagios experts have developed better tools to make monitoring easier and more precise due to dissatisfaction with Nagios. Nagios user find such tools particularly easy to use.
It is also advisable to rethink and consolidate your IT monitoring activities as a part of a conversion. Nagios is old, nevertheless it also provides some good guidelines for your strategies. Many modern tools are based on approaches from Nagios. With the right monitoring software almost all parts of Nagios monitoring can be adopted or even improved.
TL;DR:
Nagios is outdated for modern IT monitoring, pushing organizations toward more scalable and user-friendly alternatives.
- Nagios’s legacy design and manual setup make it difficult to scale, maintain, and train staff.
- Modern tools provide auto-discovery, dashboards, and cloud/container integration, reducing effort and errors.
- Other open source options broaden adoption, support enterprise workflows, and avoid lock-in.
- Migrating enables streamlined monitoring, more automation, and DevOps alignment.
Monitoring is easier today without Nagios
Other monitoring tools were already in existence when Nagios came on the market in 1999. However, Nagios unified important mechanisms for monitoring complex IT infrastructures more efficiently.
Nagios has always required some previous experience of working on the Linux console. When Nagios appeared, it was still relatively normal that IT admins could specialize in a few applications. Since then, however, the number of IT tools has grown steadily, while the staff numbers in IT departments have not increased to the same degree. The time required to learn how to use Nagios has thus become more and more of an imposition for IT teams, and is no longer sustainable.
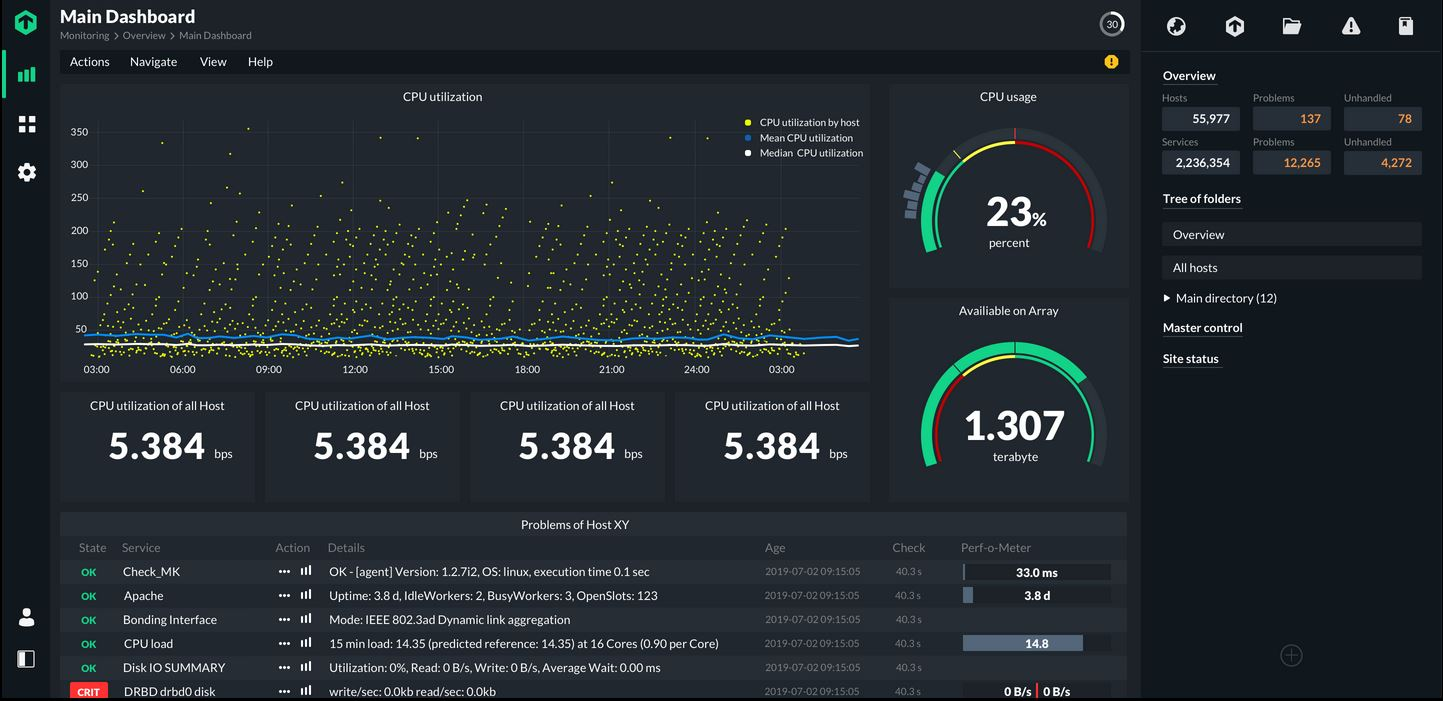
These days, most software vendors focus on reducing IT complexity and minimizing the workload for users. IT monitoring should not be an exception. By now, the code base and the architecture of Nagios are outdated and no longer state-of-the-art. Working with Nagios-Config-Files has always been uncomfortable, but today it is particularly backward. In addition, working with plug-ins and add-ons in Nagios does not meet modern standards. Updates, documentation and customization require a lot of fine-tuning, are prone to errors and are consequently somewhat outside the mainstream.
At the very latest, when you try to pass on your Nagios knowledge to new employees, you realize how difficult Nagios makes your life. Especially in the IT sector, however, you have to be prepared for personnel changes, as many companies are looking for specialists in this area. Therefore, monitoring software must be intuitive to work with so that no lengthy training is necessary.
IT has changed and monitoring needs to scale like never before
In addition, IT environments are becoming increasingly complex and a growing number of people benefit from monitoring that is easy to use. The many manual processes in Nagios are a real problem, especially with regard to new technologies and the limitations for potential users who are not members of IT Teams.
The cause is often to be found in Nagios' outdated architecture. Although Nagios is built as an extendable framework, the administration of its plug-ins and add-ons is time-consuming and resembles a vicious circle. With every update, the configuration effort increases. Over the past few years, Nagios has delivered small improvements time and again, but it lags behind in development compared to other tools. It is becoming increasingly difficult for Nagios to keep up with the dynamics of the modern IT world.
These problems can be seen in the absence of scalability in Nagios. Especially with the increasing number of devices and more and more extensive networks, Nagios faces problems. A distribution of the monitoring workload over several monitoring host servers is associated with a high workload. Sooner or later you come to the point where a central administration (single point of administration) of Nagios is no longer possible. In addition, organizations often have several branches. It is difficult to configure Nagios for this. With the right alternative software for a distributed monitoring, however, IT teams can save a lot of administrative effort.
The Nagios core is still based on working with the command line. In the commercial versions of Nagios, one has tried to relieve the user with a graphic user interface, but when switching to a modern monitoring solution, users quickly realize that the administration of a monitoring can be much easier nowadays. Modern open source solutions often offer a more attractive interface than the commercial Nagios versions.
Consolidating the monitoring
In the context of a change away from Nagios to an up-to-date solution, a good opportunity becomes available to fundamentally review your own IT monitoring procedures in addition to simply replacing the tool. After many years of use, employees in some companies have continually modified the Nagios instance and Nagios plug-ins. These changes may not always have been properly documented. The monitoring process usually continues in some way, but basic knowledge about monitoring is often lacking. This can result in blind spots and inefficient IT monitoring.
A new tool should bring extensive auto discovery functions for including possible assets that were not previously captured by Nagios into the monitoring. Nagios does not provide automatic detection of services by default, and implementation via extensions is tedious. However, because more and more systems need to be monitored, a good auto-discovery is an important criterion when choosing an alternative monitoring tool.
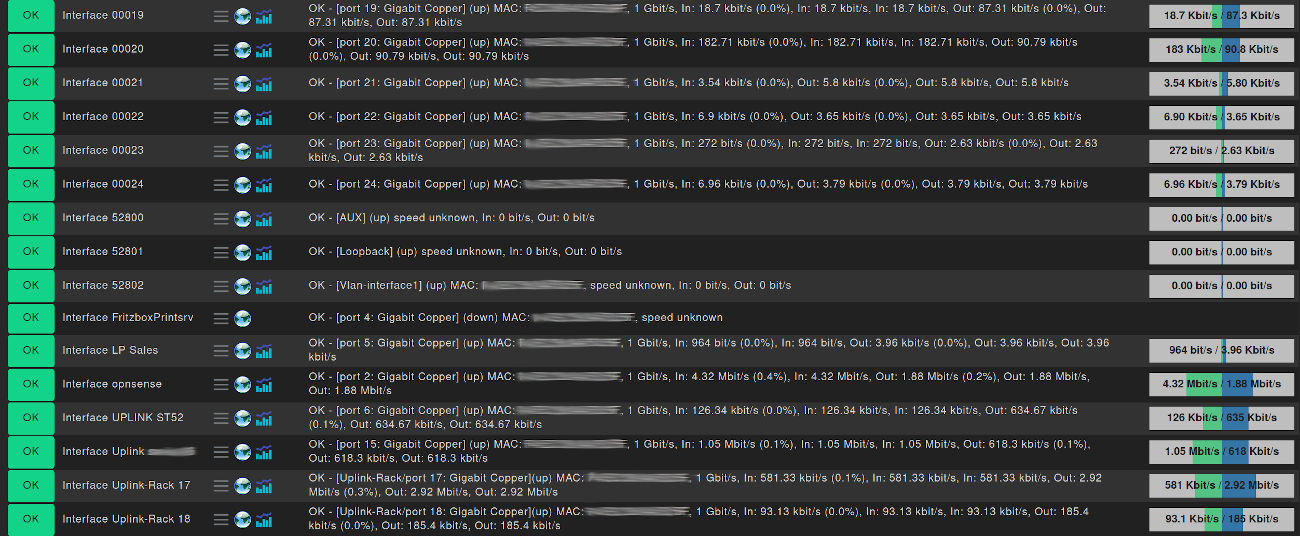
In addition, during a changeover, it is also worth checking whether certain assets are still relevant for your own organization. In the same way, the question arises as to how a new and improved approach could monitor the systems. In an ideal scenario, a new software solution would be capable of incorporating existing Nagios plug-ins, but at the same time it would also provide customized and better integrations. This is because some Nagios plug-ins are relatively old or poorly maintained. Other IT monitoring solutions bring better integrations for common technologies, which make monitoring more precise. These should then replace the old Nagios plug-ins.
Commitment to the monitoring community
Many long-time Nagios Core users are part of the open source community, and they can remember the founding of Nagios Enterprises LLC in 2007, when Nagios founder Ethan Galstad also changed some basics for working with the monitoring community. Not all community members were satisfied with this new approach. In particular, the trademark policy around the term Nagios has certainly been remembered negatively by many community members. A good connection to the community is essential for the success of a tool.
Since that time, many users have turned away from Nagios, and the support by the community is no longer optimal. Bug fixes and requests take longer or are not answered at all. Many former users of Nagios Core did not want to switch to a commercial version of Nagios, and instead decided to switch to another, open source solution, because due to its inadequate capabilities Nagios Core was no longer considered a good monitoring tool.
These days, there are open source monitoring tools available that are well suited for monitoring large environments and whose monitoring integrations are also completely open source.

Open source monitoring without extensive Linux knowledge
Windows admins find it especially difficult to work with Nagios. In particular, with Nagios Core, you have to install the Nagios Remote Data Processor on the monitoring host in addition to the Nagios agent on the target system. Time and again, this means manual work with the Linux terminal. For Windows experts, this is often a particularly difficult terrain.
However, commercial monitoring alternatives based purely on Windows are very resource-hungry and also require at least one Windows Server license. Overall, this makes them an expensive affair and does not solve all the problems that Nagios has. For example, the resource requirements of Windows as the host system usually limit the scalability of the monitoring.
Today, open source monitoring tools provide an easy entry into monitoring and can be used via docker containers or as an appliance on Windows. In addition, common tools can usually be managed via a graphical user interface. Working on the terminal is no longer necessary, or is only necessary in exceptional cases.
Clouds and containers as elements of IT infrastructure monitoring
Cloud computing, container virtualization, IoT and BYOD can only be monitored with difficulty or not at all with Nagios. A monitoring tool must not only support these technologies in principle, but also provide innovative mechanisms to make monitoring easier. The monitoring of public cloud providers is also important, for example to be able to check service level agreements (SLA) for service providers.
If organizations can spare any of their IT monitoring experts' time at all, they would have to integrate AWS or Microsoft Azure into Nagios with a lot of effort, but in practice it is difficult to implement. Even then, Nagios delivers insufficient metrics because it is not designed for monitoring cloud assets. Hybrid monitoring with Nagios therefore does not make sense.
However, it is appropriate to monitor on-premises infrastructure and cloud assets together in an alternative tool. To do this, you should be able to set up the monitoring tool in your own infrastructure, and it should also have integrations for the interfaces of the common public cloud providers.
Checkmk is easy to configure but also really flexible for all kinds of special requirements.
Monitoring as a door-opener for modern IT approaches
Cloud technologies and modern approaches such as DevOps or agile software development are changing the requirements for IT monitoring. However, Nagios is not suitable for reconciling the different monitoring approaches of IT admins and developers. This is precisely one of the key challenges for organizations.
Organizations should keep in mind that container virtualization is on the rise and that their IT infrastructure is changing as a result of this. Strictly speaking, even the basic work processes in the area of IT operations and software development are changing. Therefore, container monitoring or Docker monitoring is not only a matter of the technical limitations of Nagios, but also of missing integration possibilities between different teams.
Modern approaches should enable IT admins to respond to the requirements of developers in a targeted manner. Many monitoring tools for developers focus strongly on individual metrics, e.g. they highlight any performance problems with applications. With the right approach, IT operation teams can provide valuable insights into the causes of problems by applying their infrastructure know-how. However, this is only possible with an integrated monitoring approach.
Wider acceptance and use of monitoring without Nagios
The introduction of agile methods for the development of software is just one example of the expansion of the user base of monitoring tools. Of course, IT operation teams are still responsible for monitoring the IT infrastructure, but analysts and managers also benefit from meaningful visualizations of the monitoring data.
Although it is possible to build multiple dashboards in Nagios via extensions, their administration is again time-consuming and must be maintained by experienced Nagios users. Modern monitoring solutions provide customizable visualization options 'out-of-the-box'. Through the use of tailored adaptation for specific user groups, considerably more employees can benefit from the monitoring information.
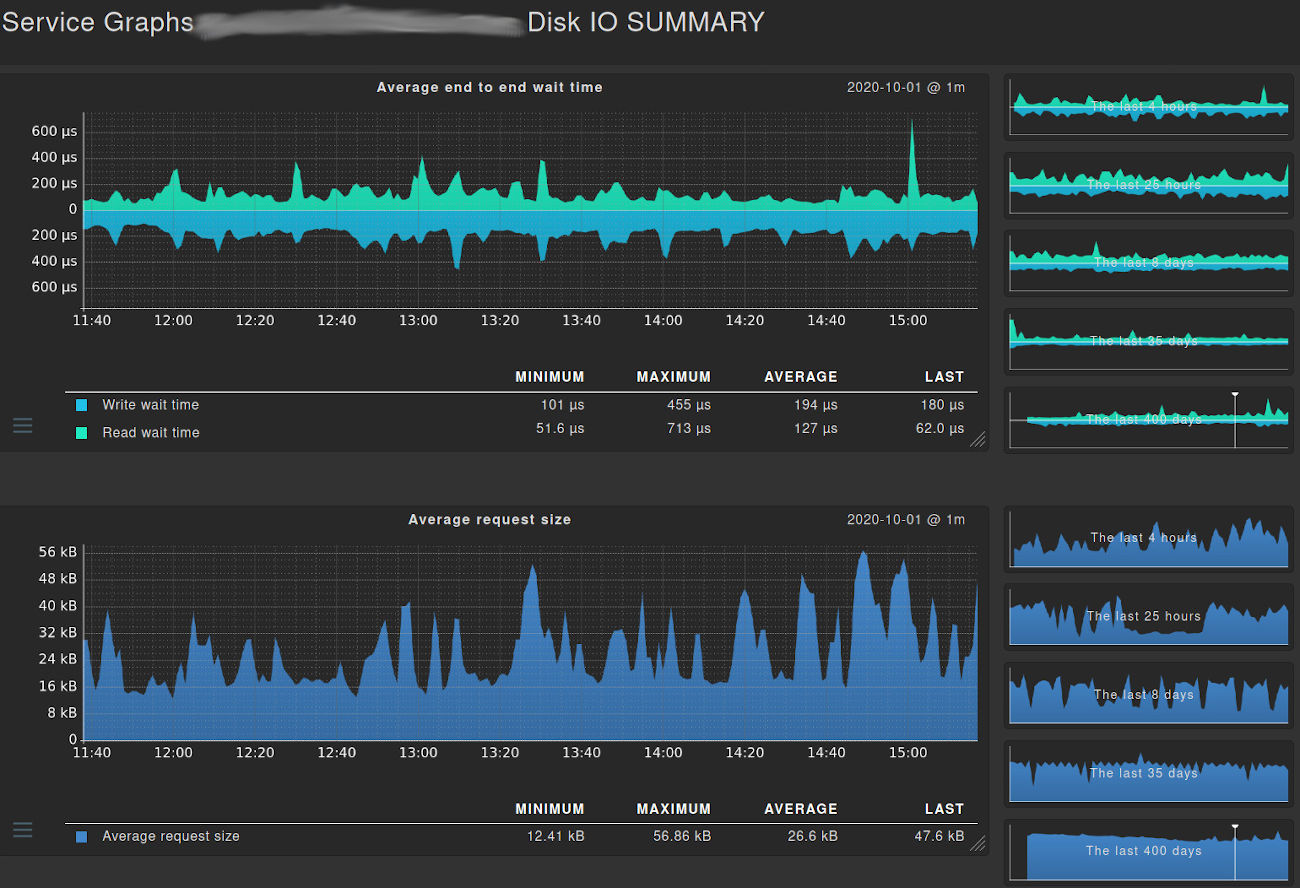
Monitoring of enterprise environments
Over time, many companies have switched from Nagios Core to a commercial Nagios version. Nagios has tried to address some problems here, but due to its advanced age, even the commercial version of Nagios has some limitations. These days, there are solutions in the category of enterprise monitoring which better meet these companies' requirements.
Modern professional tools are easier to administer and are more scalable. Moreover, you do not need additional databases, but can set up and operate them out-of-the-box. With Nagios, the integration into a modern software ecosystem is accompanied by the manual maintenance of plug-ins. In contrast, new monitoring tools are much easier to integrate with enterprise applications such as ServiceNow, Jira or Slack.
Another problem with Nagios is the issue of the high availability (HA) of monitoring. Common enterprise monitoring tools offer simple solutions via suitable monitoring clusters with a manageable workload to ensure fail-safe IT monitoring.
We are monitoring IT infrastructure from UPSs over servers, hypervisors, network, SAN and NAS storage up to the operating systems and databases, as well as SAP for over 80 customers with Checkmk and have made excellent experiences.
What to consider when migrating from Nagios to a new tool
When choosing a Nagios alternative, the first consideration is to simplify monitoring and to reduce manual tasks – host administration with Nagios is too complex. In addition, a monitoring tool must be adaptable to different use cases and must also be suitable for users without extensive monitoring experience.
Nagios has always had problems with interruptions, for example for maintenance work, or in the event of problems with the database being used. Ideally, the desired alternative should be easy to set up, and should not require any additional software. Dependencies on databases or complex configuration make monitoring error-prone and should not be necessary. In any case, a backup of the deployed database must be made before switching to a new monitoring solution.
A good open source solution is well suited not only as a successor to the Nagios Core, but also to commercial Nagios versions. A good balance is the use of an open source monitoring tool that does not impose a limit on the number of services or plug-ins used. In this way, organizations do not run the risk of path dependency.
Purely proprietary tools always carry the risk that after a complex implementation, the manufacturer may have to adjust the pricing. A proprietary system also leads to a much higher dependency on the manufacturer for integrations and interfaces, and that there is no possibility of adapting the monitoring yourself.
Ready to explore the full feature set of Checkmk?
Download the free trial and see it in action.